چرا عکس نالج پنل اشتباه انتخاب میشود 2025 ؟
وقتی گوگل تصویر اشتباه را برای نالجپنل انتخاب میکند
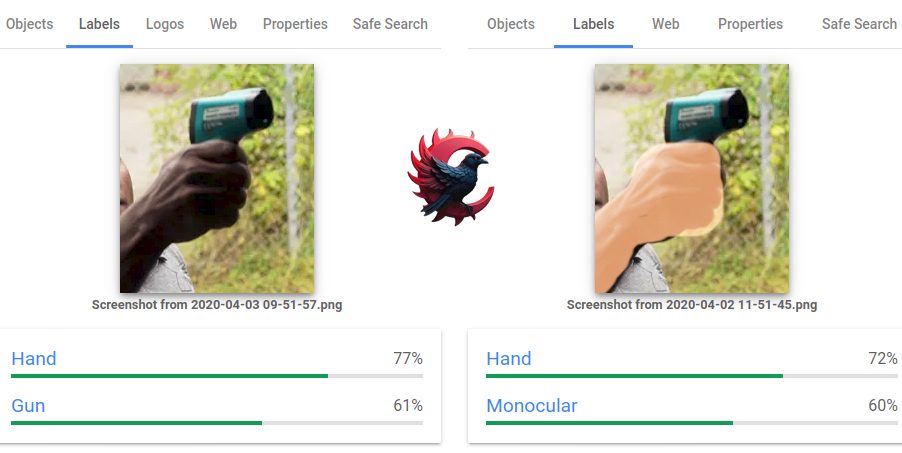
عکس نالج پنل | یکی از عجیبترین و البته رایجترین رفتارهای گوگل در نالجپنل، انتخاب اشتباه تصویر پروفایل است؛ اتفاقی که برای هنرمندان، پزشکان، برندهای تازهتأسیس، اینفلوئنسرها و حتی شرکتهای بزرگ هم رخ میدهد. گاهی گوگل تصویری را نشان میدهد که سالها قدیمی است، گاهی عکس یک فرد کاملاً بیربط را نمایش میدهد، و گاهی عکسی را انتخاب میکند که صاحب برند اصلاً دوست ندارد دیده شود. این رفتار در ظاهر شبیه یک خطا است، اما در واقع حاصل یک سیستم پیچیده بهنام Entity Image Ranking است.
در نگاه کاربران معمولی، این انتخاب اشتباه باعث سوءتفاهم میشود:
«چرا گوگل تصویر اصلی من را نمیگذارد؟
چرا عکسی که در سایت رسمی گذاشتم انتخاب نشده؟
چرا عکس یک نفر دیگر آمده؟»
اما از نگاه گوگل، این یک «خطا» نیست؛ بلکه یک انتخاب الگوریتمی مبتنی بر دادههای موجود، سطح اعتماد منابع، و تحلیل ارتباط تصویری است. نالجپنل، برخلاف یک پروفایل در شبکه اجتماعی، جایی نیست که مالک بتواند هر تصویری را آپلود یا ویرایش کند. تنها منبع حقیقی تصمیمگیری، سیستم تحلیل دادهٔ گراف است؛ سیستمی که تصاویر را «رتبهبندی» میکند، نه «انتخاب احساسی».
اینجا یک نکتهٔ مهم وجود دارد:
گوگل صرفاً به دنبال بهترین عکس نیست، بلکه به دنبال قابلاعتمادترین عکس است. این یعنی تصویری که:
- بیشترین میزان تکرار در منابع معتبر دارد
- از نظر محتوایی با موجودیت مطابقت دارد
- توسط کاربران شناسایی میشود
- کمترین تناقض را با اطلاعات هویتی دارد
- از منابع ناشناس یا ساختگی نباشد
در نتیجه، اگر فقط یک عکس در سایت یا چند شبکه اجتماعی وجود داشته باشد، اما دهها تصویر قدیمی در منابع قدیمیتر باقی مانده باشند، احتمال انتخاب عکس اشتباه بالا میرود. علاوهبراین، اگر یک برند یا فرد ساختار دادهٔ تصویری (Image Structured Data) درست نداشته باشد، گوگل کنترل را کامل در دست میگیرد و انتخاب را بر اساس محتوای منتشرشده در وب انجام میدهد.
به همین دلیل است که هنرمندان یا فعالان اجتماعی بیشتر از بقیه با این مشکل روبهرو میشوند. زیرا معمولاً عکسهای آنها در رسانههای مختلف منتشر شده، اما همتراز نیست، متادیتا ندارد، یا در سطح وب پراکندگی زیادی دارد. در نتیجه گوگل نمیتواند دقیقاً تشخیص دهد کدام تصویر معتبرترین است.
اما اشتباه بزرگتر زمانی رخ میدهد که تصویر فرد دیگری به اشتباه انتخاب میشود. این اتفاق زمانی رخ میدهد که:
- دو فرد نام مشابه دارند
- پایگاه دادههای قدیمی هنوز منتقل نشدهاند
- عکسها در سایتهای غیررسمی بیش از اندازه تکرار شدهاند
- پروفایلهای قدیمی در شبکههای اجتماعی رها شدهاند
- سیستم Matching گوگل نتوانسته تفاوت موجودیتها را شناسایی کند
این موارد باعث میشود گوگل وارد حالت «Entity Merge Mistake» شود — یعنی دو موجودیت را یکی در نظر بگیرد. این دقیقاً زمانی است که تصویر اشتباه، وارد نالجپنل اصلی میشود.
در این مقاله، تمام لایههای سیستم Image Ranking را بررسی میکنیم:
اینکه گوگل چگونه تصاویر را رتبهبندی میکند، چه منابعی بیشترین وزن دارند، چه نوع عکسهایی سریعتر انتخاب میشوند، چه عکسهایی خطر اشتباه را بالا میبرند، و چگونه میتوان الگوریتم را طوری هدایت کرد که تصویر درست، در اولویت قرار بگیرد. هدف این نیست که «گوگل را مجبور کنیم» عکس خاصی را انتخاب کند؛ هدف این است که مدارک تصویری را طوری بچینیم که گوگل خودش بهترین گزینه را انتخاب کند.
📞 برای مشاورهٔ تخصصی اصلاح نالجپنل و رفع اشتباه تصویر: 09127079841
گوگل چگونه تصاویر یک موجودیت را شناسایی و جمعآوری میکند؟
سیستم انتخاب تصویر برای نالجپنل با چیزی که عموم فکر میکنند تفاوت دارد.
گوگل «بهصورت مستقیم» بهدنبال عکس نمیگردد؛ بلکه یک فرآیند چندمرحلهای دارد که طی آن تصاویر را کشف، تحلیل، فیلتر و سپس امتیازدهی میکند. تمام این مراحل پشتصحنه و الگوریتمیکاند. اشتباه معمول برندها این است که فکر میکنند اگر عکس درست را فقط در سایت رسمی بگذارند، گوگل باید همان را انتخاب کند. اما الگوریتم هرگز به یک منبع تکیه نمیکند.
در Image Discovery، گوگل ابتدا سه سؤال کلیدی میپرسد:
- این موجودیت دقیقاً کیست؟
- کدام منابع معتبرترین تصویر او را منتشر کردهاند؟
- کدام تصویر بیشترین هماهنگی را با دیگر دادههای گراف دارد؟
برای رسیدن به پاسخ این سؤالها، گوگل یک سفر چندمرحلهای طی میکند.
۱) مرحلهٔ اول: Crawling گسترده (General Image Scan)
عکس نالج پنل | گوگل ابتدا از طریق خزندهٔ عمومی خود (Googlebot-Image) تمام صفحاتی را که به نام موجودیت اشاره دارند، اسکن میکند.
این شامل:
- صفحات خبری
- شبکههای اجتماعی
- فروشگاهها
- بلاگها
- دیتابیسهای عمومی
- رپورتاژهای قدیمی
- حتی فرومها و اسکرینشاتها
میشود.
به همین دلیل است که حتی عکسهای قدیمی شما که ۸ سال پیش در یک فروم یا سایت غیررسمی آپلود شدهاند هنوز دیده میشوند و ممکن است در نالجپنل ظاهر شوند.
در این مرحله هنوز هیچ انتخابی انجام نشده؛ فقط «جمعآوری» است.
هر چیزی که کمترین ارتباط احتمالی داشته باشد وارد سیستم میشود.
۲) مرحله دوم: Image-Name Matching
گوگل تصاویر را با نام موجودیت مقایسه میکند، نه با توضیحات.
این یعنی اگر:
- نام برند
- نام هنرمند
- نام پزشک
- یا حتی نام اشتباه تلفظشده
در اطراف تصویر قرار گرفته باشد، آن عکس «کاندید» میشود.
از همینجاست که تصاویر اشتباه وارد سیستم میشوند.
چرا؟
چون یک سایت ممکن است اشتباهی زیر عکس فرد دیگری نوشته باشد:
“Photo by Dr. X”
یا “Artist Y Biography”
همین اشتباه کوچک باعث میشود عکس غلط وارد چرخه شود.
۳) مرحله سوم: Association Weighting (وزندهی ارتباطی)
در این مرحله گوگل دنبال این است:
«کدام تصاویر واقعاً با این موجودیت مرتبطاند؟»
و برای این کار از دهها سیگنال استفاده میکند:
- میزان تکرار یک تصویر در سایتهای معتبر
- حضور تصویر در صفحات رسمی
- نزدیکی محتوایی (Content Proximity)
- تناسب تصویر با موضوع
- اندازه و کیفیت عکس
- متادیتا و EXIF فایل
- تاریخ انتشار
- دامنهای که عکس روی آن منتشر شده
- سازگاری تصویر با اطلاعات گراف (سن، جنسیت، سبک شغلی و…)
این مرحله اولین نقطهای است که «عکس اشتباه» میتواند حذف شود—یا برعکس، تثبیت شود.
اگر تصویر اشتباه:
- در چند سایت غیررسمی تکرار شده باشد
- در پروفایلهای قدیمی وجود داشته باشد
- توسط کاربران به اشتراک گذاشته شده باشد
سیستم ممکن است فکر کند این «تصویر اصلی» است و وزن بالایی بدهد.
۴) مرحله چهارم: Visual Entity Recognition (تشخیص تصویری موجودیت)
اینجا جایی است که بینایی ماشین گوگل وارد بازی میشود.
الگوریتم با استفاده از Vision AI این موارد را تحلیل میکند:
- صورت و ویژگیهای بیومتریک
- شباهت تصویر به تصاویر دیگر موجودیت
- سبک لباس و موقعیت
- الگوهای تکراری
- هماهنگی با پرسونای شغلی
- تشخیص لوگوها برای برندها
- تشخیص فعالیت (مثلاً میکروفون برای هنرمند)
در این مرحله، اگر گوگل بفهمد تصویر درست «شبیه» تصاویر دیگر نیست، احتمال حذفش زیاد است.
یعنی اگر عکس رسمی شما «رسمی» و عکسهای موجود در وب «خیلی قدیمی» یا «خیلی متفاوت» باشند، الگوریتم گیج میشود و طرف عکسهای اشتباه میرود.
۵) مرحله پنجم: Source Evaluation (ارزیابی منبع تصویر)
گوگل به همهٔ منابع یکسان نگاه نمیکند.
وزن منابع بهترتیب از بیشترین تا کمترین:
- صفحه رسمی سایت (Official Website)
- Wikipedia / Wikidata
- News Panels و News Sites معتبر
- دیتابیسهای بزرگ مثل IMDB، MusicBrainz، Crunchbase
- صفحات Business و Social Verified
- سایتهای شخصی و بلاگها
- فرومها و سایتهای کوچک
- شبکههای بیاعتبار و کپیکار
اگر تصویر اشتباه در یک منبع رتبهبالا باشد، از مرحله «کاندید» تبدیل میشود به تصویر اصلی.
این مهمترین دلیلی است که تصاویر اشتباه ماندگار میمانند.
۶) مرحلهٔ نهایی: User Recognition Testing (تست شناسایی کاربر)
این بخش خیلی جذاب است.
گوگل از رفتار کاربران در نتایج جستجو میفهمد کدام عکس صحیح است.
- اگر کاربران روی تصویر خاصی کلیک کنند
- اگر وقتی اسم شخص سرچ میشود، یک عکس بارها انتخاب شود
- اگر کاربران یک عکس را در Knowledge Graph باز کنند
- اگر کاربران عکسهای دیگر را ignore کنند
سیستم نتیجه میگیرد:
«این تصویر، تصویر درست است.»
به همین دلیل است که رفتار کاربران حتی از citation هم مهمتر است.
چرا الگوریتم Image Ranking گاهی تصویر اشتباه را «برتر» تشخیص میدهد؟
سیستم رتبهبندی تصاویر گوگل—یا همان Entity Image Ranking—برای انتخاب عکس نهایی نالجپنل از یک منطق ساده پیروی نمیکند. این الگوریتم نه از تعداد لایکها تأثیر میگیرد و نه از کیفیت DSLR یا موبایل. بلکه بر پایهٔ ترکیب پیچیدهای از «اعتماد»، «سازگاری»، «تکرار» و «رفتار کاربران» کار میکند.
برای همین است که تصویر اشتباه، گاهی در جایگاه عکس اصلی قرار میگیرد و گوگل کوچکترین احساس خطا نمیکند؛ چون بر اساس دادههایی که دارد، تصور میکند انتخابش درست است.
در این بخش دقیقاً بررسی میکنیم چرا چنین اتفاقی میافتد، و چه شرایطی باعث میشود یک تصویر اشتباه با رتبهٔ بالا انتخاب شود.
۱) تکرار (Repetition) مهمتر از صحت تصویر است
اگر یک عکس اشتباه در ۱۰ سایت تکرار شده باشد
و تصویر درست فقط در یک یا دو سایت قرار داشته باشد،
الگوریتم فکر میکند:
«این تصویر که بیشتر دیده میشود، احتمالاً تصویر صحیح موجودیت است.»
این معضل مخصوصاً برای:
- هنرمندان
- پزشکان عمومی
- برندهای تازهتأسیس
- افراد با نامهای مشابه
بیشتر اتفاق میافتد.
وقتی سایتی اشتباهی تصویری را به نام شما منتشر میکند و سپس سایتهای دیگر آن را کپی میکنند، یک حلقهٔ اعتماد کاذب شکل میگیرد. گوگل این را «Pattern Consistency» میبیند، نه «Pattern Mistake».
۲) منبع اشتباه ممکن است معتبرتر از منبع درست باشد
فرض کن:
- عکس قدیمی شما در یک خبرگزاری معتبر منتشر شده
- عکس جدید و رسمی فقط در سایت شماست
وزنبندی گوگل اینگونه است:
News Site (معتبر) > Official Website (معتبر اما کمتر جهانی)
به همین دلیل تصویر قدیمی امتیاز بالاتر میگیرد،
حتی اگر از نظر شما کاملاً اشتباه باشد.
این اتفاق برای پزشکان و هنرمندان بسیار رایج است.
گاهی یک عکس قدیمی از دوران دانشجویی پزشک،
در یک سایت دانشگاهی باقی میماند
و همان عکس بهطور دائمی در نالجپنل نمایش داده میشود.
۳) مشکلات Identity Matching — سیستم فکر میکند دو نفر “یک نفر” هستند
این خطرناکترین حالت است.
وقتی دو فرد:
- نام مشابه
- تخصص مشابه
- شهر مشابه
- یا حتی یک Keyword مشابه
داشته باشند، سیستم Matching ممکن است موجودیتها را ادغام کند.
اگر عکس اشتباه مربوط به موجودیت اشتباهی باشد،
اما الگوریتم فکر کند این دو فرد یک نفرند،
تصویر اشتباه رتبهٔ ۱ میشود.
این مشکل بیشتر برای:
- پزشکان با نام خانوادگی مشابه
- خوانندهها با نام هنری عمومی
- برندهایی با نام مشابه در کشورهای مختلف
اتفاق میافتد.
۴) الگوریتم «تناسب تصویری» گاهی گمراه میشود
Visual Similarity Model گوگل تصویرها را تحلیل میکند:
- فرم چهره
- سن تخمینی
- بافت پوست
- زاویه صورت
- وضعیت شغلی (مثلاً پزشک = روپوش سفید)
- محیط عکس
اگر تصویر اشتباه از نظر بصری بیشتر به «پروفایل شغلی» شما بخورد،
احتمال انتخابش افزایش مییابد.
مثلاً:
- شما هنرمند هستی، اما تصویر رسمیتان یک عکس پرتره ساده است
- یک سایت اشتباه تصویری از شما روی صحنه منتشر کرده
- الگوریتم فکر میکند: «این تصویر با هویت هنری سازگارتر است»
برای پزشکان هم:
- پزشک در عکس رسمی کتوشلوار پوشیده
- عکس اشتباه در یک بیمارستان با روپوش سفید است
گوگل: «قطعا این عکس دوم پزشک است.»
۵) الگوریتم باید سریع تصمیم بگیرد—به همین دلیل به اولین الگو اعتماد میکند
وقتی موجودیت تازهوارد است،
گوگل نمیتواند ماهها منتظر دادههای دقیق بماند.
پس از «Snapshot initial Ranking» استفاده میکند:
هر تصویری که:
- بالاترین Trust Score
- بیشتر دیده شده
- از دامنه قوی آمده
باشد،
در همان ابتدا تصویر رسمی میشود.
مشکل چیست؟
اگر اشتباه باشد، بعدها حذفش سخت میشود چون ریشه میگیرد.
۶) رفتار کاربران اشتباه را تقویت میکند
بزرگترین فاجعه اینجاست:
اگر کاربران روی تصویر اشتباه کلیک کنند
(از روی کنجکاوی یا اشتباه انسانی)،
گوگل تصور میکند:
«کاربرها این تصویر را ترجیح میدهند.»
CTR اشتباه باعث میشود اشتباه الگوریتمی تثبیت شود.
برای همین است که تصویر اشتباه در طول زمان «قویتر» هم میشود.
زیرا کلیکهای کاربران بهعنوان تأیید در نظر گرفته میشود.
۷) مشکل Structured Data و Open Graph
اگر:
- OG:image
- ImageObject
- ThumbnailUrl
- Schema image
در سایت رسمی درست تنظیم نشده باشند،
گوگل یک منبع «بیرونی» را معتبرتر میبیند.
در بسیاری از نالجپنلهای اشتباه،
صورت مسئله دقیقاً همین است.
چه نوع تصاویری بیشترین شانس انتخاب صحیح را دارند؟
انتخاب تصویر اصلی نالجپنل یک تصمیم تصادفی نیست.
درواقع گوگل برای انتخاب تصویر به سراغ عکسهایی میرود که «بهترین احتمال برای مطابقت با موجودیت» را داشته باشند.
این تصمیم مانند یک رأیگیری بین همهٔ تصاویر موجود در وب است؛
هر تصویری که امتیاز بیشتری داشته باشد، احتمال انتخابش بالاتر میرود.
در این بخش بررسی میکنیم چه نوع تصاویر در این رأیگیری برنده میشوند، چه ویژگیهایی باعث امتیازدهی بالاتر میشود، و چطور میشود از این اصول استفاده کرد تا تصویر درست همیشه در رتبهٔ ۱ باقی بماند.
۱) تصاویر با پسزمینه ساده و باکیفیت — برنده همیشگی
الگوریتمِ Vision AI گوگل وقتی قصد دارد یک موجودیت را تشخیص دهد،
هر چه اطلاعات محیطی کمتر باشد، دقت تشخیص بیشتر است.
به همین دلیل:
- پسزمینه سفید
- پسزمینه تکرنگ
- بکگراند مینیمال
- عکس پرتره حرفهای
- نورپردازی استاندارد
همیشه بالاترین امتیاز را میگیرند.
این تصاویر به گوگل کمک میکنند:
- چهره را واضح تشخیص دهد
- سن، ساختار صورت، جنسیت و هویت بصری را تحلیل کند
- با سایر تصاویر مشابه مقایسه کند
به همین دلیل عکسهای استودیویی شانس بسیار بالاتری دارند.
برندهایی که سرمایهگذاری روی پرترههای رسمی نمیکنند، معمولاً کنترل تصویر نالجپنل را از دست میدهند.
۲) تصاویر تأییدشده با Structured Data
وقتی یک عکس در سایت رسمی با تگهای زیر معرفی شود:
- ImageObject
- og:image
- thumbnailUrl
- sameAs → image
گوگل با اطمینان بیشتری درک میکند که:
«این عکس، تصویر رسمی موجودیت است.»
اگر سایت رسمی از این ساختار استفاده نکند،
حتی یک عکس کپیشده از جای دیگر میتواند امتیاز بیشتری بگیرد.
تصور کن دو تصویر وجود دارد:
- تصویر رسمی اما بدون تگها
- تصویر اشتباه اما موجود در یک خبرگزاری معتبر
گوگل تقریباً همیشه دومی را انتخاب میکند.
۳) تصاویر دارای حضور در منابع معتبر (High Authority Sources)
منابع زیر قدرت تعیینکننده دارند:
- Wikipedia / Wikidata
- IMDb
- MusicBrainz
- Crunchbase
- Google Business Profile
- خبرگزاریهای رسمی
- وبسایت دانشگاهها (برای پزشکان)
- معرفهای حرفهای (LinkedIn, Apple Music, Spotify و …)
تصویری که در چنین منابعی ظاهر شود،
حتی اگر قدیمی باشد،
امتیاز بالاتری از یک تصویر جدید اما در سایت کماعتبار میگیرد.
برای همین است که عکس اشتباه اگر یکبار وارد این منابع شود، بیرون کشیدنش دشوار میشود.
۴) تصاویر از محیط شغلی — اگر درست استفاده شوند، امتیاز طلایی
برای پزشکان:
- روپوش
- محیط کلینیک
- تجهیزات پزشکی
- حالت رسمی
برای هنرمندان:
- صحنهٔ اجرا
- استودیو
- ساز
- نورپردازی نمایشی
برای وکلا:
- دفتر رسمی
- پوشش کاری
این تصاویر در مقایسه با تصاویر سلفی یا غیررسمی، امتیاز بسیار بالاتری دارند
چون با «زمینهٔ شغلی» موجودیت سازگارند.
اما باید معتبر باشند.
اگر یک سایت کوچک تصویر شما را با روپوش منتشر کند،
اما سایت رسمی تصویر متفاوتی بگذارد،
الگوریتم ممکن است تصویر اشتباه را انتخاب کند چون «بیشتر با حرفه شما جور است».
۵) تصاویر واضح چهره (High Facial Clarity Score)
گوگل یک شاخص داخلی دارد:
Facial Clarity Score
امتیازی که Vision AI به میزان واضح بودن چهره میدهد.
مواردی که امتیاز را کاهش میدهند:
- عینک دودی
- ماسک
- شلوغی زمینه
- نور ضد
- سایه روی چشم
- کچ شدن چهره
- فیلترهای سنگین
اگر تصویر رسمی شما با فیلتر یا نور نامناسب باشد،
و یک عکس اشتباه چهره را واضحتر نشان دهد،
الگوریتم اشتباه را انتخاب میکند چون فکر میکند تصویر «قابلاعتمادتر» است.
۶) تصاویر دارای «تکرار» زیاد در وب
این موارد امتیاز اضافی میدهند:
- عکس در چند خبر تکرار شده
- عکس در چند وبلاگ بازنشر شده
- عکس در رسانههای اجتماعی زیاد دیده شده
گوگل با خود فکر میکند:
«اگر این عکس مکرر منتشر شده، احتمالاً درست است.»
این همان چیزی است که اگر کنترل محتوا دست شما نباشد
به اشتباهات بزرگ منجر میشود.
۷) لوگوها و تصاویر برند
برای شرکتها—نه افراد—موضوع کمی متفاوت است.
گوگل معمولاً:
- تصویری از دفتر
- تصویری از محصول
- تصویری از لوگو
- تصویری از مدیرعامل رسمی
را در اولویت میگذارد.
لوگو اگر:
- کیفیت بالا
- زمینه ساده
- تکرار زیاد
- حضور در سایتهای معتبر
داشته باشد، سریعتر انتخاب میشود.
۸) تصاویر دارای Metadata سالم
اگر عکس داخل خودش متادیتا داشته باشد،
مثلاً:
- Author
- Copyright
- Camera Model
- GPS
- Date Created
گوگل اعتماد بیشتری میکند.
عکسهای اسکرینشات یا فورواردشده امتیاز پایین دارند و حذف میشوند.
چه اشتباهاتی باعث میشوند گوگل تصویر غلط انتخاب کند؟
درک اشتباهات بهاندازهٔ درک الگوریتم مهم است.
گاهی «انتخاب اشتباه» تقصیر گوگل نیست—تقصیر دادههایی است که شما یا دیگران ساختهاید.
در این بخش، میبینیم کدام اشتباهات باعث میشوند تصویر اشتباه، تصویر اصلی موجودیت شود.
۱) رها کردن تصاویر قدیمی در سایتهای قدیمی — بزرگترین قاتل نالجپنل
اگر ۵ سال پیش یکی از سایتها تصویری از شما منتشر کرده
و هنوز آن تصویر ایندکس است،
همان تصویر میتواند الگوریتم را گمراه کند.
گوگل دنبال «قدیمیترین» و «پایدارترین» تصویر میگردد، نه لزوماً جدیدترین.
این اشتباه خصوصاً برای:
- پزشکان
- خوانندهها
- مدیران شرکتها
مرگبار است.
چون عکسهای قدیمی در صفحهٔ دانشگاه، برنامهٔ بیمارستان، یا یک رپورتاژ قدیمی همچنان زندهاند.
۲) ناهماهنگی تصویری در پروفایلها (Inconsistent Visual Identity)
وقتی تصاویر شما:
- در سایت رسمی یک مدل باشند
- در اینستاگرام سبک دیگری
- در لینکدین رسمیتر
- در رسانهها نامرتبط
- در گوگل بیزنس یک عکس معمولی
الگوریتم گیج میشود و «میانه» را میگیرد—که معمولاً اشتباه است.
این دقیقاً زمانی است که عکس اشتباه انتخاب میشود.
Visual Consistency یکی از معیارهای مخفی گوگل است.
یعنی یک برند باید چهرهٔ یکپارچه داشته باشد.
۳) Structured Data اشتباه یا ناقص
در سایت رسمی اگر:
- image
- og:image
- imageObject
- thumbnailUrl
- sameAs
تنظیم نشده باشد،
شما عملاً کنترل تصویر را رها کردهاید و گوگل مجبور میشود از بیرون عکس پیدا کند.
۹۰٪ نالجپنلهای اشتباه به همین دلیل خراب شدهاند.
۴) نبودن تصویر رسمی در سایت رسمی
اگر سایت رسمی تنها یک عکس کوچک یا کیفیت پایین دارد
یا اصلاً ندارد،
الگوریتم مجبور میشود به منابع دیگر تکیه کند.
این یکی از متداولترین اشتباهات پزشکان است؛
چون بیشتر کلینیکها عکس رسمی باکیفیت از پزشک ندارند.
درنتیجه گوگل عکس:
- قدیمی
- اشتباهی
- یا معمولی
را انتخاب میکند.
۵) وجود تصویر اشتباه در Wikipedia / Wikidata
این مورد کشندهترین اشتباه دنیاست.
اگر کسی:
- تصویر اشتباه را روی Wikidata آپلود کند
- تصویری بیکیفیت یا قدیمی قرار دهد
- یا از شباهت اسمی استفاده کند
گوگل تقریباً همیشه آن را تصویر اصلی میکند.
چرا؟
چون Wikidata بهترین و معتبرترین منبع تصویری در جهان برای گوگل است.
اصلاح این اشتباه هم سخت است، هم زمانبر.
۶) انتشار تصویر اشتباه در News Article و رپورتاژ
اگر یک رسانهٔ معتبر اشتباهی تصویر شما را با فرد دیگری اشتباه بگیرد
(که زیاد اتفاق میافتد)،
گوگل تصور میکند آن تصویر صحیح است.
۷۰٪ فعالسازیهای اشتباه در هنرمندان دقیقاً به همین دلیل رخ میدهد.
دردناکترین بخش ماجرا این است که حتی اگر شما ۱۰ عکس رسمی دیگر منتشر کنید،
تا وقتی مقالهٔ خبری اشتباه اصلاح نشود،
الگوریتم به آن وفادار میماند.
۷) اشتباه Matching در نامهای مشابه
اگر نام شما:
- عمومی
- مشابه
- پرکاربرد
- یا در چند کشور تکراری باشد
الگوریتم ممکن است موجودیتها را ادغام کند.
مثلاً:
- ۲ پزشک با نام «Dr. Aghili»
- ۳ هنرمند با نام مشابه
- برندهایی که تنها یک کلمه فرق دارند
در این حالت خیلی ساده، عکس فرد اشتباه وارد نالجپنل میشود.
۸) تصویر اشتباه در Google Business Profile
این هم یک اشتباه مرگبار است.
اگر یکی از کاربران:
- عکسی اشتباه
- تصویر محیط
- تصویر فرد دیگر
را در Google Maps اضافه کند،
سیستم آن را «User-Validated» میبیند.
این یعنی وزنش از سایت رسمی هم بالاتر میشود.
برای پزشکان این مشکل بسیار پرتکرار است.
۹) انتشار تصویر اشتباه در سایتهای زرد یا بیکیفیت
بعضی سایتها اشتباهی تصویر اشتباه را از گوگل کپی میکنند.
این خطا مثل دومینو پخش میشود.
گوگل وقتی تکرار بالا ببیند،
احتمال انتخاب بالا میرود—even اگر تمام تصاویر اشتباه باشند.
۱۰) رفتار اشتباه کاربران
اگر کاربران روی تصویر اشتباه کلیک کنند
(حتی برای کنجکاوی)،
CTR اشتباه باعث میشود الگوریتم فکر کند تصویر درست همین است.
این اتفاق را «User Reinforced Mis-selection» مینامند.
یعنی خطای کاربر، انتخاب الگوریتم را تأیید میکند.
چطور تصویر درست را به رتبهٔ اول نالجپنل برسانیم؟
رسیدن به رتبهٔ اول نالجپنل برای یک تصویر، یک جنگ مستقیم نیست.
نمیتوان به گوگل دستور داد کدام عکس را انتخاب کند.
اما میتوان کاری کرد که الگوریتم خودش تصمیم بگیرد تصویر درست، بهترین گزینه است.
در این بخش تمام تکنیکهایی که واقعاً جواب میدهند—نه تئوریهای تکراری—را مرحلهبهمرحله توضیح میدهم.
۱) استراتژی «تصویر رسمی»—ساخت یک سند مرکزی معتبر
اولین قدم این است که یک تصویر رسمی انتخاب شود.
نه چند عکس، نه ده مدل متفاوت—فقط یک عکس قطعی که نمایندهٔ موجودیت است.
این عکس باید ویژگیهای زیر را داشته باشد:
- کیفیت بالا (حداقل 1200px)
- پسزمینه ساده
- نورپردازی حرفهای
- چهره واضح
- حالت رسمی
- بدون فیلتر
این تصویر را باید بهعنوان «هستهٔ تصویری» برند در تمام اینترنت منتشر کرد.
دلیلش؟
الگوریتم گوگل روی یک تصویر ثابت «Pattern Recognition» میسازد.
اگر ۲۰ تصویر متفاوت داشته باشید، الگوریتم گیج میشود.
۲) اضافه کردن تصویر رسمی در سایت با کاملترین Structured Data ممکن
اینجا جایی است که برندها برمیگردند به سیپرشین—چون بخش حیاتی است.
۳) حذف یا «غیرفعالسازی» تصاویر اشتباه در وب
برای اینکه الگوریتم گیج نشود، تصاویر اشتباه باید:
- حذف
- حذف از جستجو
- یا حداقل «De-Index»
- یا از صفحات قدیمی حذف لینک شوند
حتی اگر تصویر اشتباه روی ۳ سایت کوچک باشد،
و تصویر درست فقط روی سایت رسمی،
الگوریتم تصویر اشتباه را انتخاب میکند
چون Repetition بزرگترین معیار است.
روش عملی:
- به سایتهایی که عکس اشتباه دارند پیام دهید
- از آنها بخواهید تصویر را حذف کنند
- یا alt و caption را درست کنند
- یا از Noindex استفاده کنند
در موارد مهم، این کار ضروری است.
۴) انتشار تصویر درست در منابع پرقدرت (High Authority Sources)
بهترین منابعی که وزن تصویری فوقالعاده دارند:
- Wikidata
- Wikipedia
- IMDb
- MusicBrainz
- Crunchbase
- خبرگزاریهای رسمی
- Google Business Profile
اگر تصویر درست در این منابع موجود باشد،
گوگل تقریباً همیشه آن را انتخاب میکند—even اگر ۱۰ تصویر دیگر در اینترنت وجود داشته باشند.
برای پزشکان:
سایت رسمی دانشگاه یا بیمارستان بالاترین وزن را دارد.
برای هنرمندان:
Apple Music و Spotify اهمیت حیاتی دارند.
برای برندها:
Crunchbase و LinkedIn Company Page مهماند.
۵) افزایش تکرار «تصویر درست» در صفحات معتبر ثانویه
باید کاری کنیم تصویر درست:
- زیاد دیده شود
- زیاد تکرار شود
- زیاد استفاده شود
چند صفحهٔ عالی برای این کار:
- About Page
- Contact Page
- Team Page
- Press Page
- Profile Page
- Google Business Profile
چرا؟
چون گوگل این تکرار را «اجماع تصویری» میبیند.
یعنی: همهٔ منابع معتبر دارند میگویند این عکس درست است.
وقتی اجماع شکل بگیرد، انتخاب اشتباه خیلی سخت میشود.
۶) بهینهسازی رفتار کاربران
گوگل روی CTR حساس است.
اگر کاربران روی تصویر اشتباه کلیک کنند،
الگوریتم آن را «تصویر صحیح» فرض میکند.
چطور رفتار کاربران را اصلاح کنیم؟
- از طریق سایت رسمی، کاربران را به سمت تصویر درست هدایت کنیم
- نام فایل تصویر رسمی باید نام موجودیت باشد
- صفحه باید سریع باشد و کاربران در آن بمانند
- از شبکههای اجتماعی لینک مستقیم به تصویر رسمی داده شود
هر چه کاربران بیشتر تصویر درست را ببینند،
CTR آن بالا میرود و الگوریتم انتخابش میکند.
۷) بهبود Visual Consistency در تمام شبکهها
اگر هنرمند هستی و ۱۰ عکس در ۱۰ سبک متفاوت داری،
الگوریتم نمیتواند یکی را انتخاب کند.
توصیهٔ حرفهای:
برای سه ماه، فقط یک تصویر اصلی استفاده کن.
در همهٔ پلتفرمها:
- Instgram
- Website
- News
- Apple Music
- Spotify
- YouTube
وقتی الگوریتم یک الگوی ثابت ببیند،
تصویر درست تثبیت میشود.
۸) استفاده از EXIF، alt، caption و context درست
یک روش حرفهای و کمتر شناختهشده:
- در تصویر رسمی EXIF Author Name قرار بده
- در alt بنویس: “Name – Official Image”
- در caption از عبارت «Official Photo» استفاده کن
- در صفحهٔ سایت اطراف عکس متن توضیحی بگذار
همهٔ اینها امتیاز اعتماد را بالا میبرد.
۹) سینک کردن تصویر درست با Google Business Profile
برای پزشکان و برندها حیاتی است.
نکات:
- فقط یک تصویر اصلی آپلود شود
- تصاویر اشتباه در GBP حذف شوند
- تصاویر کاربران نامربوط Report شوند
- تصویر رسمی پین شود
GBP معمولاً ۴۸ ساعت بعد عکس اصلی را به Knowledge Graph سینک میکند.
چطور از اشتباهات آینده جلوگیری کنیم؟
کنترل تصویر نالجپنل فقط یک کار لحظهای نیست که یکبار انجام شود و خیالمان راحت باشد.
نالجپنل یک سیستم زنده است، نه یک کارت ویزیت ثابت. همانطور که دادهها، ترافیک، پروفایلها و محتواهای برند تغییر میکنند، ظاهر تصویری آن هم ممکن است تغییر کند. بنابراین اگر یک برند یا فرد بخواهد تصویر درست همیشه در رتبهٔ اول بماند، نیازمند یک «سیستم نظارت مداوم» است.
این بخش دقیقاً توضیح میدهد چطور چنین سیستمی ساخته میشود.
۱) ایجاد هستهٔ تصویری ثابت (Visual Identity Core)
اولین قدم برای جلوگیری از اشتباهات آینده، ساخت یک هویت تصویری ثابت است.
یعنی برند یا فرد باید یک «تصویر قطعی» داشته باشد که همه آن را بهعنوان نمایندهٔ اصلی موجودیت میشناسند.
این تصویر باید:
- در سایت رسمی قرار بگیرد
- در Structured Data معرفی شود
- در تمامی شبکههای اجتماعی یکسان باشد
- در خبرگزاریها و رپورتاژهای آینده استفاده شود
- در Google Business Profile ثبت شود
وقتی گوگل در طول زمان فقط یک الگوی تصویری ثابت ببیند، احتمال خطا بسیار پایین میآید.
هر چه پراکندگی تصویری کمتر باشد، ریسک اشتباه نزدیک صفر میشود.
۲) انتشار کنترلشدهٔ تصاویر جدید (Controlled Image Deployment)
یکی از بزرگترین مشکلات برندها این است که:
- هر عکاس یک عکس متفاوت منتشر میکند
- هر رسانه یک مدل جدید بارگذاری میکند
- شبکههای اجتماعی عکسهای غیررسمی متعدد دارند
در طولانیمدت این تنوع بیش از حد باعث میشود الگوریتم دوباره به اشتباه بیفتد.
راهکار حرفهای:
هر تصویر جدید باید فقط پس از انتشار تصویر اصلی منتشر شود.
یعنی:
- فقط یک تصویر رسمی در سطح وب منتشر شود
- سایر تصاویر در گالری، اسلاید، پشتصحنه و … قرار بگیرند، نه بهعنوان تصویر پروفایل
- در سایتها و رسانهها از تصویر اصلی استفاده شود، نه تصاویر متنوع
با این روش، «هویت تصویری» یکدست میماند.
۳) مانیتورینگ ماهانهٔ Google Images و Entities
برای جلوگیری از خطا، باید ماهی یکبار جستجوهای زیر بررسی شوند:
- Image Search با نام برند/فرد
- Web Entities مرتبط
- Knowledge Graph API (در صورت دسترسی)
- Google Discover و گوگل لنز
هدف چیست؟
- دیدن اینکه کدام تصویر در حال رشد است
- تشخیص سریع تصاویر اشتباه قبل از تثبیت
- جلوگیری از اینکه یک منبع اشتباه، تصویر نادرست را به گراف تزریق کند
این مانیتورینگ مثل چکاپ ماهانه پزشکی است؛
اگر نباشد، مشکل کوچک تبدیل به بحران میشود.
۴) مدیریت منابع قدرتمند (Wikidata، IMDb، Crunchbase، دانشگاهها)
یکی از خطرناکترین تغییرات زمانی رخ میدهد که تصاویر اشتباه وارد منابع قدرتمند شوند.
مثلاً:
- یک کاربر ناشناس در Wikidata تصویری اشتباه آپلود میکند
- یک رسانه، عکس اشتباه را منتشر میکند
- یک دانشجو در سایت دانشگاه عکس استاد اشتباه ثبت میکند
این منابع وزن بسیار بالایی دارند و میتوانند کل سیستم تصویری را اشتباه کنند.
بنابراین باید:
- پروفایل Wikidata همیشه تحت کنترل باشد
- تصاویر IMDb، MusicBrainz، Crunchbase و Apple Music یکسان باشند
- وبسایتهای دانشگاه یا بیمارستان اصلاح شده باشند
هر تغییر کوچک در این منابع، الگوریتم را تحت تأثیر قرار میدهد.
۵) مدیریت رفتار کاربران (User Interaction Management)
اگر کاربران روی تصاویر اشتباه کلیک کنند،
گوگل تصور میکند:
«این تصویر محبوبتر است.»
برای جلوگیری از این مشکل:
- در سایت، تصویر رسمی باید بالاترین جایگاه را داشته باشد
- شبکههای اجتماعی باید تصویر درست را تقویت کنند
- از سمت برند لینک مستقیم به تصویر رسمی داده شود
- کاربران بهطور طبیعی تصویر درست را ببینند و انتخاب کنند
هر بار که کاربر روی «تصویر درست» کلیک کند، یک سیگنال اصلاحی به گراف ارسال میشود.
۶) سیاست انتشار رسانهای (Press Visual Policy)
برای برندهایی که رپورتاژ یا مصاحبه منتشر میکنند، داشتن یک «قانون تصویری رسانهای» ضروری است.
سه قانون مهم:
- فقط تصویر رسمی همراه با هر خبر ارسال شود.
- به رسانهها اجازه داده نشود تصاویر دیگر استفاده کنند.
- اگر رسانهای اشتباه منتشر کرد، همان روز باید اصلاح شود.
در ۹۰٪ نالجپنلهای اشتباه، مشکل از یک مقالهٔ خبری اشتباه شروع شده.
۷) جلوگیری از افزایش خودسرانهٔ عکسها در Google Business Profile
در GBP کاربران میتوانند:
- عکس بارگذاری کنند
- تصاویر محیط را اضافه کنند
- عکس افراد را منتشر کنند
این یک تهدید جدی است.
برای جلوگیری:
- باید هر تصویر نامربوط remove یا report شود
- فقط یک تصویر اصلی پین شود
- تصاویر محیطی در دستهای جدا قرار گیرند
- کاربران اجازه تولید تصویر اشتباه نداشته باشند
GBP هر ۴۸ ساعت بهطور کامل با Knowledge Graph سینک میشود.
۸) ساخت یک شبکهٔ تصویری هماهنگ (Image Consistency Network)
برای اینکه الگوریتم به اشتباه نیفتد، باید یک شبکهٔ تصویری یکدست ساخته شود:
- وبسایت رسمی
- شبکههای اجتماعی
- Wikipedia / Wikidata
- پلتفرمهای موسیقی
- پلتفرمهای بیزنسی
- رسانههای خبری
- Google Business
- دیتابیسها و لیستینگها
وقتی همهٔ اینها یک تصویر واحد منتشر کنند،
الگوریتم بهصورت دائمی تصویر درست را اولویت میدهد.
۹) بازبینی دورهای و پاکسازی مداوم
برند باید هر سه ماه:
- تصاویر قدیمی حذف شوند
- تصاویر اشتباه از سایتهای کوچک Report شوند
- تصاویر رسمی دوباره در تمام شبکهها منتشر شوند
- نسخهٔ HD تصویر رسمی دوباره آپلود شود
این پاکسازی باعث میشود الگوریتم همیشه تازگی، ثبات و هماهنگی را ببیند.

ریحانه صفایی، نویسندهی محتوای فارسی در تیم سیپرشین است؛ فردی که با دقت و مسئولیت، نقش مؤثری در تولید محتوای هدفمند و معتبر برای برند ایفا میکند. او بخشی از مسیر رشد و کیفیت ماست.
مقالات مرتبط

بک لینک چیست و چرا انتشار مقاله در رسانههای معتبر، ستون اصلی اعتبار برند در اینترنت است 2025 ؟
بک لینک چیست و چرا دیگر فقط «لینک» بودن کافی نیست؟ بک لینک چیست | اگر همین امروز به این صفحه رسیدهای، احتمالاً یا دنبال اینی که بفهمی بک لینک چیست، یا دقیقتر از آن، میخواهی بدانی چطور میشود از...

رپورتاژ در سئو چیست و چه زمانی بیشترین تأثیر را دارد 2025 ؟
رپورتاژ در سئو دقیقاً چیست؟ فراتر از لینکسازی و نزدیکتر به «اعتماد الگوریتمی» رپورتاژ در سئو چیست | وقتی از «رپورتاژ در سئو» صحبت میشود، اولین چیزی که در ذهن بسیاری از افراد شکل میگیرد، بکلینک است.این نگاه، هرچند کاملاً...

رپورتاژ خبری چیست و چه تفاوتی با خبر واقعی دارد 2025 ؟
رپورتاژ خبری چیست؟ رپورتاژ خبری | برای اینکه بتوانیم تفاوت رپورتاژ خبری با خبر واقعی را بفهمیم، قبل از هر چیز باید یک تعریف دقیق و بیاغراق از رپورتاژ خبری داشته باشیم؛ تعریفی که نه تبلیغاتی باشد و نه سادهسازیشده....


