
چطور اسامی مستعار نالج پنل باعث سردرگمی می شنود 2025 ؟
وقتی نامهای متفاوت یک موجودیت را تکهتکه میکنند
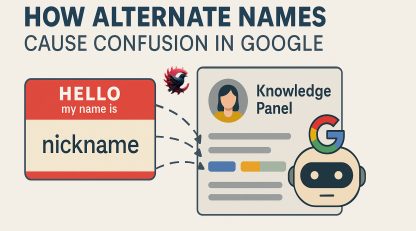
اسامی مستعار نالج پنل | اگر بخواهیم گوگل را مثل یک انسان تصور کنیم، او موجودیتی را از طریق «الگوها» و «ثبات» میشناسد؛ نه احساس و حدس. گوگل نمیتواند حدس بزند که فلانی در همه جا نامهای متفاوت دارد اما همان یک نفر است. تنها چیزی که میبیند، دادههایی است که از وب جمع میکند.

اینجا نقش «Alternate Names» شروع میشود؛ همان نامهای مستعار، کوتاهشده، انگلیسی/فارسی، نام هنری، نام سازمانی، یا حتی غلطنویسیهایی که کاربران و سایتها منتشر کردهاند.
مشکل اینجاست:
وقتی گوگل چند نام متفاوت برای یک موجودیت ببیند، نمیتواند بهطور قطعی بگوید همهی این اسامی مربوط به یک شخص هستند. در نتیجه:
- موجودیت را تکراری میبیند
- پروفایلها را جداگانه ثبت میکند
- سیگنالها پخش میشوند
- نالجپنل فعال نمیشود یا دیر فعال میشود
- یا بدتر: موجودیت اشتباهی به موجودیت شما چسبیده میشود
این رفتار یک مفهوم کلیدی دارد: Entity Fragmentation
یعنی «تکهتکه شدن هویت» در چشم موتور جستجو.
مثال ساده:
فرض کن نام کامل شخص Ali Jafari است.
اما در وب این نامها دیده میشود:
- Ali Jafari
- A. Jafari
- Ali Jafary
- علی جعفری
- استاد جعفری
- Alijafari_official
- Jafari Artist
از نگاه انسان همهی اینها یک نفر هستند.
اما از نگاه ماشین؟
«هفت موجودیت متفاوت با احتمال ارتباط.»
همین تعدد اسامی باعث میشود گوگل مجبور شود از الگوریتم Matching استفاده کند؛ همان جایی که خطا رخ میدهد. اگر الگوریتم موفق نشود تمام نامهای شما را به یک «Entity ID» متصل کند، نتیجهاش یکی از اینهاست:
- نالجپنل دیرتر فعال میشود
- نالجپنل اصلاً فعال نمیشود
- نالجپنل دورهای ناپدید میشود
- عکس و اطلاعات اشتباه نمایش داده میشود
- نالجپنل ناقص و کماطلاعات است
- نالجپنل اشتباهی به نام شخص دیگر ساخته میشود
چیزی که برای برندها و افراد عمومی فاجعهآمیز است:
گوگل از Alternate Names برای درک موجودیت استفاده نمیکند، بلکه برای «تطبیق» استفاده میکند.
و اگر این نامها زیاد، پراکنده و ناهماهنگ باشند، Matching درست انجام نمیشود.
در عصر ۲۰۲۵ که گوگل، Gemini، ChatGPT و Perplexity از Knowledge Graph مشترک تغذیه میکنند، بحران بزرگتر میشود:
اسامی مستعار اشتباه، پاسخهای اشتباه تولید میکنند.
چرا؟
چون AI ها فرض میکنند هر نامی یک موجودیت جداست مگر اینکه مدارک قطعی خلافش را ثابت کنند.
در چنین شرایطی، برندهایی که نامهای پراکنده دارند، تبدیل میشوند به موجودیتهایی با «هویت چندلایه» که برای الگوریتمها قابل اعتماد نیستند. این موضوع مستقیماً بر فعالسازی نالجپنل تأثیر میگذارد.
در این مقاله بررسی میکنیم:
- چرا تعدد نامها گراف را گمراه میکند؟
- چگونه یک موجودیت بهاشتباه با موجودیتهای مشابه ادغام میشود؟
- چه نامهایی مضر هستند و باید حذف شوند؟
- نقش Wikidata در یکسانسازی نامها چیست؟
- چگونه ساختار نامگذاری (Name Schema) فعالسازی نالجپنل را سرعت میدهد؟
- و در نهایت، چطور باید هویت اسمی را استاندارد کرد تا گوگل همیشه موجودیت را یکسان بشناسد؟
📞 برای مشاوره و ساخت نالجپنل بدون سردرگمی اسمی: 09127079841
چطور گوگل هویت واقعی موجودیت را تشخیص میدهد و چرا نامهای متعدد این سیستم را مختل میکنند؟
برای اینکه بفهمیم چرا اسامی مستعار میتوانند ساخت نالجپنل را به تعویق بیندازند یا آن را کاملاً مختل کنند، باید دقیقاً وارد قلب سیستم تشخیص موجودیت گوگل (Entity Resolution System) شویم. گوگل تنها با «اسم» کار نمیکند؛ بلکه با «هویت» کار میکند. و هویت برای گوگل مجموعهای از سیگنالهای همگراست، نه یک واژه واحد.
۱) «String Matching» در مقابل «Entity Matching»
اسامی مستعار نالج پنل | گوگل دو مسیر برای تشخیص هویت دارد:
مسیر اول: String Matching
یعنی تطبیق حروف با یکدیگر.
در این روش، گوگل صرفاً نامها را مقایسه میکند و اگر اختلاف زیاد باشد، فرض میکند اینها دو فرد متفاوت هستند.
مثال:
Ali Jafari ≠ A. Jafari
Ali Jafari ≠ Ali Jafary
Ali Jafari ≠ Alijafari_official
این اختلافات کوچک برای انسان واضح و بیاهمیت است، اما برای الگوریتم متنی، «معنا» ندارند. الگوریتم فقط به شباهت ظاهری کاراکترها نگاه میکند.
مسیر دوم: Entity Matching
در این مسیر گوگل تلاش میکند بفهمد آیا دو نام ظاهراً متفاوت، به یک موجودیت واحد تعلق دارند یا نه.
اینجاست که اشتباهات رخ میدهد.
سیستم Entity Matching باید اطلاعاتی مانند:
- شبکهٔ بکلینکها
- ساختار پروفایلها
- نوع فعالیت
- رسانههایی که نام را ذکر کردهاند
- الگوی انتشار محتوا
- حضور در دیتابیسهای معتبر
را بررسی کند تا بفهمد آیا این نامها در نهایت به یک «Entity ID» ختم میشوند یا خیر.
وقتی تعداد اسامی زیاد شود، حجم پردازش و احتمال خطا بالا میرود.
۲) مفهوم Entity Ambiguity — ابهام هویتی
اگر یک برند ۷ نام متفاوت در وب داشته باشد، گوگل مجبور میشود بررسی کند که اینها:
- یک موجودیت هستند؟
- یا چند موجودیت مشابه؟
- یا چند شخصیت متفاوت که فقط نامهای شبیه دارند؟
در زبان فنی، این وضعیت «Entity Ambiguity» نام دارد.
یعنی: هویت آنقدر مبهم است که قابل ردیابی نیست.
این ابهام معمولاً در ۳ حالت به وجود میآید:
حالت اول: تغییر مداوم اسامی در شبکههای اجتماعی
مثلاً:
- OfficialAli
- AliTheArtist
- RealAliJafari
- AliJafariStudio
این تغییرها باعث میشود گوگل پروفایلها را «منفصل» ببیند.
حالت دوم: تفاوت زبان
مثلاً کسی که همزمان با این نامها حضور دارد:
- علی جعفری
- Ali Jafari
برای الگوریتمی که باید اطلاعات را به زبانهای مختلف پیوند دهد، این موضوع پیچیدگی ایجاد میکند.
حالت سوم: وجود نامهای مشابه توسط دیگر افراد
اگر ۵ نفر در دنیا اسمشان Ali Jafari باشد، آنگاه الگوریتم Matching باید تشخیص دهد کدام یک از اینها «شما» هستید.
اگر اسامی مستعار شما نامناسب باشد، الگوریتم به اشتباه موجودیت دیگران را با شما یکی میکند.
۳) نقش Platform Consistency — یکپارچگی پلتفرمها
گوگل همیشه با یک سؤال مهم مواجه است:
«آیا نامهایی که در شبکههای اجتماعی، سایتها، دیتابیسها و اخبار منتشر شده، واقعاً به یک فرد اشاره دارد؟»
اگر پاسخ قطعاً بله نباشد، نالجپنل فعال نمیشود.
مثال:
وبسایت → Mohammad Reza Zahedi
اینستاگرام → RezaZahedi.music
لینکدین → M. Reza Z
آپارات → رضا زاهدی
اینها برای ما واضح است، ولی برای موتور جستجو چهار هویت متفاوت هستند که باید «ادغام» شوند. ادغام اگر ناقص انجام شود، موجودیت اصلی شناسایی نمیشود؛ در نتیجه نالجپنل نمیآید.
۴) نقش Citationهای پراکنده
چنانچه وبلاگها یا سایتهای کوچک شما را با اسامی متفاوت معرفی کنند، الگوریتم Matching اساساً از هم میپاشد.
چرا؟
چون Citationهای کوچک (در مقایسه با رسانههای خبری بزرگ) وزن پایینتری دارند، اما تعداد زیادشان با نامهای مختلف، سیگنال غلط تولید میکند.
مثلاً:
- یک سایت نوشته “Ali Jaffari”
- دیگری نوشته “Ali Jafari Artist”
- یکی نوشته “Ali Jafari (CEO)”
سه نام مختلف.
سه کانتکست مختلف.
سه فعالیت مختلف.
نتیجه؟
سیستم تصمیم میگیرد اینها سه فرد مختلف هستند.
۵) چرا این مشکل، فعالسازی نالجپنل را عقب میاندازد؟
گوگل برای فعالسازی نالجپنل باید «اعتماد» داشته باشد. این اعتماد از ثبات دادهها ساخته میشود.
وقتی نامها متعدد و پراکنده باشد:
- اعتماد پایین میآید
- Entity ID ساخته نمیشود
- یا نیمهساخته باقی میماند
- یا ادغام نادرست اتفاق میافتد
- یا نالجپنل شما موقت ایجاد میشود و دوباره حذف میشود
به زبان ساده:
اسامی مستعار ناهماهنگ، دشمن فعالسازی نالجپنل هستند.
تأثیر اسامی مستعار بر اعتماد الگوریتم و مفهوم Name Stability Score
برای اینکه بفهمیم چرا تعدد اسامی مستعار باعث میشود گوگل در فعالسازی نالجپنل دستبهعصا حرکت کند، باید یک لایه بالاتر برویم؛ لایهای که گوگل در آن «امتیاز ثبات نام» یا همان Name Stability Score را محاسبه میکند. این امتیاز همان معیاری است که تعیین میکند یک موجودیت چقدر قابلشناسایی، قابلاعتماد و قابلاتصال به دیتابیسهای دیگر است. هرچه این امتیاز پایینتر باشد، احتمال ساخت نالجپنل نزدیک به صفر میشود—even اگر شخص یا برند بسیار شناختهشده باشد.
۱) گوگل چگونه الگوی ثبات نام را اندازهگیری میکند؟
گوگل هزاران منبع آنلاین را بررسی میکند تا ببیند «کدام نام» با بیشترین تعداد سیگنال معتبر همراه است. این بررسی شامل:
- پروفایلهای رسمی
- صفحات وبسایت
- رسانههای خبری
- دیتابیسها
- شبکههای اجتماعی
- وبلاگها
- بکلینکها
میشود. هر نامی که در این منابع بهصورت «یکپارچه» تکرار شود، امتیاز بالاتری میگیرد.
اما اگر یک برند، فرد یا سازمان در هر منبع با یک نام متفاوت حضور داشته باشد، الگوریتم عملاً نمیتواند تشخیص دهد کدام یک نام واقعی است.
مثلاً:
- وبسایت: Ali Jafari
- لینکدین: A. R. Jafari
- اینستاگرام: AliJafari.official
- یوتیوب: JafariMusic
- مقالات خبری: Ali Reza Jafari
برای انسان قابلدرک است که همه اینها میتوانند به یک شخص اشاره کنند، اما برای الگوریتم هیچ قطعیتی وجود ندارد. وقتی قطعیت پایین باشد، «Name Stability Score» پایین میآید و گوگل بهطور خودکار وارد حالت Risk Mode میشود.
در این حالت، سیستم ترجیح میدهد هیچ نالجپنلی نمایش ندهد تا اینکه اطلاعات اشتباه نشان دهد.
۲) رابطهٔ ثبات نام و Entity Linking
در لایهٔ بعدی، گوگل باید نامها را به ساختارهای دیگر وصل کند:
- ویکیدیتا
- گوگلبوکس
- گوگلاسکالر
- IMDb
- MusicBrainz
- Crunchbase
- Wikipedia
- سایت رسمی
- گراف دانش داخلی گوگل
وقتی اسامی یک برند یا فرد متناقض باشند، این «لینکسازی موجودیتی» (Entity Linking) انجام نمیشود.
این یعنی:
- فعالیتهای آنلاین شما
- سوابق شما
- محتواهای مربوط به شما
- لینکهای خارجی شما
بهصورت یک «پروفایل واحد» دیده نمیشود.
در نتیجه موجودیت شما در سیستم تبدیل به یک «جیمیل بدون صاحب» میشود: وجود دارد، اما قابلتأیید نیست.
۳) چطور اسامی مستعار، سیگنالهای Trust را تخریب میکنند؟
سیستم اعتماد گوگل (Trust System) به ۴ بخش تقسیم میشود:
۱) Source Trust — اعتماد به منبع
اگر ۲۰ سایت معتبر شما را با یک نام بنویسند اما اینستاگرام شما نام دیگری داشته باشد، الگوریتم دچار تناقض میشود.
2) Context Trust — اعتماد به زمینه
اگر نامهای مختلف در زمینههای مختلف به کار بروند—مثلاً نام A برای موزیک و نام B برای کسبوکار—سیستم فرض میکند دو فرد متفاوت هستید.
3) Temporal Trust — اعتماد زمانی
اگر هر ماه اسم پروفایل خود را عوض کنید، یا رسانهها در بازههای زمانی مختلف نامهای متفاوتی بنویسند، الگوریتم قادر نیست «سابقهٔ زمانی» یکپارچه بسازد.
4) Semantic Trust — اعتماد معنایی
این بخش به معنی ارتباط بین «نام» و «مفهوم فعالیت» است.
اگر Ali Jafari در یک سایت CEO باشد، در یک سایت Music Producer و در یک سایت Blogger، سیستم تشخیص میدهد احتمالاً سه فرد مختلف هستند.
وقتی این چهار لایهٔ اعتماد ضربه بخورند، اعتماد موجودیت (Entity Trust) به سطحی میرسد که سیستم نمیتواند نالجپنل ارائه دهد، چون احتمال نمایش اطلاعات غلط وجود دارد.
۴) چرا یک نامِ ثابت، مهمتر از بکلینک و رسانه است؟
جالب است که الگوی ثبات نام برای گوگل مهمتر از بسیاری از سیگنالهای دیگر است.
چرا؟
چون:
- نام، ID اولیهٔ موجودیت است.
- نام، ستون تعریف هویت است.
- نام، اولین متغیری است که برای لینکسازی به کار میرود.
- نام، کلید ادغام اطلاعات در Knowledge Graph است.
اگر این ستون لرزان باشد، همه چیز فرومیریزد—even با ۱۰۰ رپورتاژ سنگین.
این دلیل اصلی است که در پروژههای سیپرشین، قبل از شروع ساخت نالجپنل، یک مرحلهٔ کامل به نام Name Normalization انجام میشود.
در این مرحله همهٔ اسامی یکیسازی میشوند تا الگوریتم تنها یک مسیر داشته باشد و اعتماد اولیه کاملاً تثبیت شود.
۵) مثال واقعی از یک شکست موجودیتی بهخاطر اسامی مستعار
یکی از مشهورترین کیسها در سال ۲۰۲۳ این بود:
یک کارآفرین بینالمللی که در ۵ قاره مصاحبه داده بود و پروفایلش در دهها رسانه منتشر شده بود، هرگز نالجپنل نگرفت.
علت؟
- در لینکدین یک شکل از اسم
- در اینستاگرام دو شکل دیگر
- در توییتر نام متفاوت
- در وبسایت نام کامل بههمراه میاننام
- در رسانههای بینالمللی ترجمههای مختلف اسم
گوگل نمیتوانست بفهمد این فرد یک نفر است یا چند نفر.
در نتیجه نالجپنل هیچوقت فعال نشد—even با وجود صدها citation معتبر.
این دقیقاً همان چیزی است که در ایران و خاورمیانه هم زیاد اتفاق میافتد.
۶) نتیجهگیری: چرا Name Stability، شاهکلید فعالسازی نالجپنل است؟
ثبات نام باعث میشود:
- هویت یکپارچه شود
- سیگنالها همسو شوند
- الگوریتم Matching خطا نکند
- Citationها ارزش واقعی پیدا کنند
- Entity Linking کامل انجام شود
- سیستم اعتماد شکل بگیرد
و در نهایت:
نالجپنل سریعتر و پایدارتر فعال میشود.
در مقابل، نامهای متعدد، پراکنده و نامنظم باعث:
- کاهش شدید Entity Trust
- تناقض در دادهها
- تأخیر یا عدمفعالسازی نالجپنل
- حتی حذف کامل یک موجودیت فعال
میشوند.
کدام اسامی مستعار بیخطرند و کدامها موجودیت را از بین میبرند؟
وقتی دربارهٔ «Alternate Names» حرف میزنیم، اشتباه رایج این است که همهٔ اسامی مستعار را بد بدانیم. درحالیکه برای گوگل، مسئلهٔ اصلی تعدد یا وجود نام نیست؛ مسئله «الگوی معنایی و ساختاری نامها» است. گوگل با اسامی مستعار مشکل ندارد، اما با اسامی مستعار نامنظم مشکل دارد.
برای اینکه بفهمیم کدام نامها به الگوریتم کمک میکنند و کدام نامها آن را تخریب، باید به دو طبقهبندی نگاه کنیم:
- اسامی قابلقبول
- اسامی مخرب
هرکدام را دقیق و کامل توضیح میدهم.
۱) اسامی مستعار قابلقبول — Alternate Names که به نالجپنل آسیب نمیزنند
این دسته از نامها نه تنها مضر نیستند، بلکه اگر مدیریت شوند، به گوگل کمک میکنند تا موجودیت را بهتر تطبیق دهد. اینها معمولاً الگوهای «قابل پیشبینی» هستند.
۱.۱) ترجمههای رسمی و متداول
اگر نام کسی در زبانهای مختلف یکسان ترجمه شود، الگوریتم بهراحتی ارتباط را پیدا میکند.
مثال:
- علی حسینی
- Ali Hosseini
این دو نام معمولاً یک مالکیت واحد ایجاد میکنند، چون الگوی نگارشی و آوایی قابل تطبیق دارند.
۱.۲) مخففهای استاندارد
مثل:
- Mohammad → M.
- Reza → R.
- Hossein → H.
اما این نوع مخفف زمانی قابل قبول است که بهصورت مداوم در منابع رسمی تکرار شود. اگر لینکدین یک مخفف باشد و اینستاگرام نام کامل، الگوریتم کمی سختگیرتر عمل میکند اما همچنان قابلتشخیص باقی میماند.
۱.۳) لقبهایی که در متن مقالهها معنا دارند
مثلاً:
- Dr.
- Engineer
- Professor
- Artist
- Producer
اگر اینها در مقالات خبری همراه با نام کامل ذکر شوند، برای الگوریتم نشانهٔ «Contextual Alias» هستند و مشکلی ایجاد نمیکنند.
۱.۴) اسامی تجاری مرتبط با برند اصلی
برای مثال:
- C Persian
- C-Persian Agency
- C Persian VIP Branding
اینها «Commercial Alias» محسوب میشوند و تا زمانی که به وبسایت اصلی لینک داشته باشند، به گراف آسیب نمیزنند.
۲) اسامی مستعار مخرب — Alternate Names که موجودیت را از بین میبرند
این دسته خطرناک است. اینها همان نامهایی هستند که باعث:
- افت Entity Trust
- ساخت موجودیت اشتباه
- حذف نالجپنل
- سردرگمی موتورهای مکالمهای
- اشتباه در عکس یا اطلاعات
میشوند.
۲.۱) اسامی شخصی با تفاوت ساختاری شدید
مثلاً:
- Ali Jafari
- Ali Jafar
- Alijahfaari
- AjafariMusic
اینها برای انسان قابل شناخت هستند اما برای الگوریتم سه تا پنج موجودیت متفاوتاند.
۲.۲) نامهایی که با شغل یا حوزه بیربط ترکیب شدهاند
مثلاً:
- Ali Crypto
- Ali Fitness
- Ali Trader
- Ali Music Studio
- Ali Personal Vlog
اگر شما فقط خواننده هستید اما در چند نام از حوزههای مختلف استفاده کردهاید، سیستم به سرعت نتیجه میگیرد که اینها افراد متفاوتاند.
۲.۳) نامهای Brand-Like بدون اشاره به موجودیت
مثلاً:
- Infinity Records
- The Dream Studio
- Vision Lab
اگر این نامها بهطور مستقل دیده شوند و به موجودیت شخصی شما لینک نداشته باشند، سیستم یک موجودیت جدید میسازد و این موجودیت به سمت شما وصل نمیشود.
۲.۴) چند زبان بدون استاندارد واحد
مثال:
- علی جعفری
- Ali Jafari
- Ali Jafary
- Alee Jaffari
- Alijafari
اگر همگی در یک دوره زمانی منتشر شوند، باگهای Matching بیشتر میشود.
۲.5) اسامی با غلط املایی در اخبار
این خطرناکترین است.
مثلاً یک رسانهٔ خبری معتبر شما را اشتباه بنویسد:
- Ali Jafary (غلط)
چون خبر، «Citation High-Trust» محسوب میشود، گوگل به این نام غلط وزن بالایی میدهد و موجودیت اشتباهی میسازد.
۳) چه تعداد نام برای یک موجودیت «Safe» است؟
فرمول طلایی سیپرشین در پروژههای نالجپنل:
حداکثر ۳ نام استاندارد قابل قبول است
۱) نام کامل رسمی (Main Name)
۲) ترجمهٔ انگلیسی استاندارد (Standard English Form)
۳) یک نام هنری یا شغلی ثابت (Artist/Professional Alias)
بیشتر از این عملاً خطرناک است و Name Stability Score را پایین میآورد.
۴) نقش «Name Normalization» در جلوگیری از تخریب موجودیت
Name Normalization یعنی:
- انتخاب ۱ نام اصلی ثابت
- انتخاب ۱ نام انگلیسی استاندارد
- انتخاب ۱ نام مستعار حرفهای
- حذف بقیهٔ اسامی
- اصلاح اشتباهات نگارشی در وب
- بازنویسی پروفایلها
- اصلاح متادیتا
- هماهنگسازی تمام پلتفرمها
این مرحله دقیقاً کاری است که سیپرشین برای فعالسازی سریع نالجپنل انجام میدهد، چون تا زمانی که نامها تثبیت نشوند، نالجپنل قابل اعتماد نیست.
۵) چرا تعدد اسامی باعث میشود ChatGPT، Gemini و Perplexity نیز اشتباه کنند؟
در ۲۰۲۵ این سه مدل AI از Knowledge Graph مشترک استفاده میکنند.
وقتی موجودیت چند اسم متفاوت داشته باشد:
- پاسخها اشتباه میشود
- اطلاعات با افراد دیگر ادغام میشود
- عکس اشتباهی انتخاب میشود
- نقش شغلی اشتباه نسبت داده میشود
- تاریخ تولد، ملیت یا بیوگرافی مخلوط میشود
این دقیقاً همان پدیدهای است که در صنعت به آن Prompt Pollution by Ambiguous Entities میگویند.
به همین دلیل اگر نامها آماده و استاندارد نباشند، حتی بعد از فعالشدن نالجپنل، AIها نیز دچار خطای معنایی میشوند.
تأثیر اسامی مستعار بر Entity Linking و اینکه چرا برخی نامها موجودیت را به موجودیتهای اشتباه متصل میکنند
برای اینکه بفهمیم چرا اسامی مستعار میتوانند موجودیت شما را به موجودیتهای اشتباه وصل کنند، باید وارد عمیقترین لایهٔ نالجگراف شویم: لایهٔ Entity Linking.
این لایه جایی است که گوگل تصمیم میگیرد:
- «کدام اطلاعات مربوط به چه موجودیتی است؟»
- «کدام دو موجودیت یکی هستند؟»
- «کدام دو موجودیت شبیهاند اما متفاوت؟»
- «کدام اطلاعات باید ادغام شوند و کدام جدا بمانند؟»
Entity Linking مهمترین بخش ساخت نالجپنل است و اسامی مستعار یکی از مهمترین عواملی هستند که آن را بهدرستی شکل میدهند یا کاملاً نابود میکنند.
۱) Entity Linking چگونه کار میکند؟
گوگل اطلاعات خامی که در هزاران سایت مختلف وجود دارد را بررسی میکند. سپس با استفاده از الگوریتمهای:
- Matching
- Clustering
- Semantic Grouping
- Identity Resolution
- Graph-Based Merging
سعی میکند بفهمد کدام دادهها «به هم تعلق دارند». نتیجهٔ این فرآیند یک ساختار مرکزی به نام Entity ID است — چیزی که نالجپنل بر اساس آن ساخته میشود.
اما اگر نامهای متفاوت (Alternate Names) وجود داشته باشند، الگوریتم با یک معضل بنیادی روبهرو میشود:
آیا این نامها به یک فرد اشاره دارند یا چند فرد مختلف؟
این سؤال سادهترین اما مهمترین سؤال الگوریتم است. اگر پاسخ اشتباه داده شود، موجودیت بهطور کامل منحرف میشود.
۲) چگونه اسامی مستعار باعث میشوند دادههای سایر افراد به شما وصل شوند؟
در سیستم Linking، گوگل از الگوی Similarity Weight استفاده میکند. یعنی اگر دو نام از نظر ظاهری شبیه باشند، احتمال اتصال آنها بالا میرود—even اگر مربوط به دو فرد کاملاً متفاوت باشند.
مثال واقعی:
Ali Jafari
Ali Jafary
Alireza Jafari
Ali Jafari Music
Ali Jafary Crypto
از نگاه گوگل، اینها ممکن است یک فرد باشند—مخصوصاً اگر:
- فعالیتها همپوشانی داشته باشند
- سایتها و رسانههای متوسط/کوچک این نامها را اشتباه بنویسند
- بکلینکها ضعیف باشند
- پروفایلهای شبکههای اجتماعی یکدست نباشند
در نتیجه سیستم اطلاعات یک فرد دیگر را به پروفایل شما Merge میکند.
نتیجه؟
یک نالجپنل با:
- عکس اشتباه
- شغل اشتباه
- اطلاعات تحصیلی اشتباه
- تاریخ تولد اشتباه
- لینکهای اشتباه
- زبان اشتباه
- حتی Nationality اشتباه
این دقیقاً همان اتفاقی است که برای بسیاری از هنرمندان ایرانی افتاده و نالجپنلشان با افراد همنام دیگر ادغام شده است.
۳) نقش رسانههای ضعیف در ایجاد لینک اشتباه
یکی از خطرناکترین مشکلات این است:
وقتی سایتهای ضعیف یا بلاگها نام شما را اشتباهی بنویسند، گوگل این اشتباه را حذف نمیکند.
بلکه این دادهها بهعنوان «Weak Signals» در سیستم باقی میمانند.
Weak Signals + Multiple Names =
Linking Error
دو اشتباه خطرناک:
الف) رسانهٔ ضعیف نام شما را غلط مینویسد → الگوریتم این غلط را معتبر فرض میکند
مثلاً:
- Reza Jafari
- Raza Jafary
- Rezajahfari
چون الگوریتم نمیتواند تشخیص دهد غلط بوده، فرض میکند «سه فرد متفاوت» وجود دارد.
ب) رسانهٔ ضعیف شما را با فرد دیگری اشتباه میگیرد
مثلاً هنرمندی با نام مشابه.
در نتیجه سیستم برای آن فرد، Entity ID میسازد و بعد اطلاعات شما را هم به آن اضافه میکند.
۴) نقش “Semantic Drift” — تغییر معنایی خطرناک
اگر نامهای شما با زمینههای مختلف ترکیب شوند، الگوریتم دچار Semantic Drift میشود — یعنی معنی نام شما از مسیر اصلی خارج میشود.
مثلاً:
- Ali Artist
- Ali Singer
- Ali Blogger
- Ali Tech
- Ali Trader
گوگل نمیتواند تشخیص دهد کدام «Ali» شما هستید.
این Drift باعث میشود سیستم موجودیتهای اشتباه را به موجودیت شما بچسباند.
نتیجه؟
نالجپنل اشتباه، ناقص، یا حذفشده.
۵) چرا برخی نامها باعث حذف نالجپنل میشوند؟
بزرگترین دلیل حذف نالجپنل این است:
اگر الگوریتم بفهمد موجودیت بیش از حد مبهم است، نالجپنل را غیرفعال میکند.
دلیل:
- الگوریتم نمیتواند اعتماد کند
- نمیخواهد اطلاعات اشتباه نشان دهد
- Linking Error رخ داده
- Entity ID از حالت Stable خارج شده
- Citationهای متعدد با نامهای مختلف وجود دارد
- تصاویر اشتباه در حال نمایش هستند
به همین دلیل است که نالجپنل برخی افراد «هفتهای یکبار» ناپدید میشود.
ریشهٔ مشکل همیشه نامهای متعدد است.
۶) چرا گوگل برای Linking به اسامی وزن خاصی میدهد؟
نامها در الگوریتم Linking سه نوع وزن دارند:
۱) Strong Alias — نامهایی که گوگل آنها را پذیرفته
مثل نام رسمی، نام انگلیسی استاندارد، نام هنری ثابت.
۲) Soft Alias — نامهایی که شاید مربوط باشند شاید نه
نامهایی که در چند رسانهٔ کوچک دیده شدهاند.
۳) Conflicting Alias — نامهایی که باعث اختلال میشوند
نامهایی با تفاوت زیاد که معمولاً منجر به خطای Linking میشوند.
وقتی Conflicting Alias زیاد شوند:
- Entity ID شکسته میشود
- نالجپنل متوقف میشود
- سیستم وارد حالت Safe Mode میشود
- موجودیت از نتایج Knowledge Graph حذف میشود
۷) چطور یک برند میتواند از خطای Linking جلوگیری کند؟
سیپرشین معمولاً قبل از شروع ساخت نالجپنل این مراحل را انجام میدهد:
- پاکسازی نامهای اضافه
- حذف یا تغییر پروفایلهای مخرب
- اصلاح مقالات اشتباه رسانهها
- حذف Citationهای ضعیف
- اصلاح Metadata
- ایجاد یک ساختار نامگذاری واحد
- ثبت نام استاندارد در دیتابیسها
نتیجه:
الگوریتم فقط یک مسیر دارد → موجودیت یکتا → نالجپنل سریع و پایدار.
چطور از اسامی مستعار برای تقویت نالجپنل استفاده کنیم
در بخشهای قبلی دیدیم که اسامی مستعار چگونه میتوانند الگوریتم گوگل را دچار ابهام کنند، باعث ایجاد موجودیتهای اشتباه شوند یا حتی نالجپنل را از بین ببرند. اما نکتهٔ ظریفی وجود دارد:
مشکل اسامی مستعار نیست؛ مشکل اسامی مستعارِ بدون استراتژی است.
اگر این نامها درست مدیریت شوند، نه تنها خطرناک نیستند، بلکه میتوانند «سیگنالهای تقویتی» باشند و فعالسازی نالجپنل را سرعت بدهند.
در این بخش توضیح میدهم چطور برندها میتوانند از Alternate Names بهعنوان یک ابزار قوی برای تقویت هویت موجودیتی استفاده کنند.
۱) اصل طلایی: انتخاب «Anchor Name» — نام لنگر برای تثبیت موجودیت
برای اینکه اسامی مستعار تبدیل به عامل تقویت شوند، باید یک «نام لنگر» (Anchor Name) انتخاب شود.
Anchor Name همان نامی است که:
- در رسانهها
- در ویکیدیتا
- در وبسایت رسمی
- در شبکههای اجتماعی
- در دیتابیسها
- در اسکیما
- در بکلینکها
همواره ثابت تکرار میشود.
این نام ستون اصلی موجودیت است.
هر اسمی که خارج از محدودهٔ این Anchor Name باشد، نباید در سطح وب منتشر شود.
وقتی Anchor Name تثبیت شود:
- الگوریتم Matching ساده میشود
- Linking کوتاهتر میشود
- ریسک Conflicting Alias کاهش مییابد
- Name Stability Score بالا میرود
- Entity Trust تقویت میشود
- فعالسازی نالجپنل سریعتر رخ میدهد
چیزی که اکثر برندها نمیدانند این است که Anchor Name حتی مهمتر از رپورتاژ است؛ چون رپورتاژ میتواند اشتباه نوشته شود و کل سیستم را خراب کند، اما Anchor Name درست، همهچیز را اصلاح میکند.
۲) استفاده از Alternate Names بهعنوان «سیگنالهای تقویتی»
برخلاف تصور عموم، اسامی مستعار (اگر درست هدایت شوند) میتوانند یک ابزار قوی برای ایجاد ارتباطات معنایی باشند.
سه نوع Alternate Name وجود دارد که میتوانند قدرت موجودیت را افزایش دهند:
۱) Professional Alias — نامهای حرفهای مرتبط با هویت کاری
مثل:
- Dr. Ali Jafari
- Ali Jafari (Entrepreneur)
- Ali Jafari (Music Producer)
این نامها برای گوگل ارزشمندند چون «Contextual Identity» میسازند و به الگوریتم میگویند این فرد در چه حوزهای شناخته میشود.
۲) Language Variants — نگارش استاندارد در زبانهای مختلف
مثل:
- علی جعفری
- Ali Jafari
اینها میتوانند پایهٔ ارتباطات فراملی باشند و در linking بین زبانها نقش مهمی بازی کنند، بهشرطی که استاندارد باشند.
۳) Corporate Alias — نامهای تجاری مرتبط با برند
مثل:
- C Persian
- C-Persian Agency
- C Persian Branding
این نامها کمک میکنند که برند شخصی یا سازمانی، به شکل یک entity چندبُعدی در گراف تثبیت شود.
۳) حذف و پاکسازی اسامی مخرب (Entity Hygiene)
یکی از مهمترین مراحل ساخت نالجپنل در پروژههای سیپرشین، مرحلهٔ «بهداشت موجودیتی» یا Entity Hygiene است.
در این مرحله:
- نامهای اشتباه پاک میشوند
- پروفایلهای آسیبزا حذف میشوند
- نامهای غلط در رسانهها تصحیح میشود
- Citationهای اشتباه Disavow میشود
- ساختار نامگذاری یکپارچه میشود
این مرحله دقیقاً همان چیزی است که باعث میشود الگوریتم Linking بهجای ساخت موجودیتهای پراکنده، یک موجودیت واحد بسازد.
۴) چرا باید Alternate Names در اسکیما مدیریت شوند؟
Structured Data (اسکیما) به گوگل میگوید:
«این نامها همگی متعلق به یک موجودیت هستند.
حتی اگر در وب متفاوت ظاهر شده باشند.»
تقریباً همهٔ نالجپنلهایی که پایدار و موفق هستند، یک سیستم اسکیما مدیریتشده دارند.
۵) کنترل انتشار نامها — Rule of Two
در پروژههای بینالمللی سیپرشین یک قانون مهم وجود دارد:
**در وب فقط دو نوع نام باید منتشر شود:
۱) Anchor Name
۲) یک Alternate Name استاندارد**
نام سومی که در وب تکرار شود، سیستم را دوباره وارد منطقهٔ خطر میکند.
خصوصاً اگر در شبکههای اجتماعی باشد.
۶) ایجاد ارتباط معنایی بین نامها (Semantic Reinforcement)
این تکنیک پیشرفتهتر است و معمولاً برای پروژههای سطح بالا استفاده میشود.
Semantic Reinforcement یعنی:
- تولید محتواهایی که در آن Alternate Name بهصورت هوشمندانه در کنار Anchor Name ذکر شود
- ایجاد یک فضای معنایی مشترک
- آموزش الگوریتم که این اسامی به یک فرد اشاره دارند
این تکنیک باعث میشود حتی نامهایی که از نظر ظاهری متفاوتاند، در ذهن الگوریتم بهعنوان «هویت واحد» تثبیت شوند.
۷) جمعبندی نهایی — چطور نامها نالجپنل میسازند یا نابود میکنند
نامهای یکپارچه → اعتماد → Linking درست → نالجپنل پایدار
نامهای پراکنده → ابهام → Linking غلط → نالجپنل حذفشده
اگر بخواهیم مقاله را در یک جمله خلاصه کنیم:
اسامی مستعار، اگر مدیریت نشوند، هویت شما را در چشم گوگل تکهتکه میکنند؛
اگر استاندارد شوند، موجودیت شما را قدرتمند میسازند.
در سال ۲۰۲۵، وقتی موتورهای مکالمهای مثل ChatGPT، Perplexity و Gemini نیز از همین نامها برای تولید پاسخ استفاده میکنند، مدیریت Alternate Names از همیشه مهمتر است.
اگر برند یا شخص، Name Stability را کنترل نکند، کل هویت دیجیتال او در گراف دچار فروپاشی میشود.
اما اگر نامها استاندارد، هماهنگ و استراتژیک باشند، نالجپنل:
- سریعتر فعال میشود
- پایدارتر میماند
- درست آپدیت میشود
- کمتر ریسک حذف دارد
- و اطلاعات و عکس دقیقتری نشان میدهد
در نهایت، مدیریت صحیح اسامی مستعار یعنی مدیریت هویت موجودیتی.
📞 برای ساخت نالجپنل پایدار، رفع ابهام اسمی و استانداردسازی هویت موجودیت:
09127079841

زهرا عبدلی، نویسندهی محتوای فارسی در تیم سیپرشین است؛ فردی که با دقت و مسئولیت، نقش مؤثری در تولید محتوای هدفمند و معتبر برای برند ایفا میکند. او بخشی از مسیر رشد و کیفیت ماست.
مقالات مرتبط
چطور اسامی مستعار نالجپنلAlternate Names باعث سردرگمی گوگل میشوند 2025 ؟
چرا اسامی مستعار میتوانند نالجپنل را به هم بریزند؟ اسامی مستعار نالجپنل | این روزها تقریباً هر فرد یا برندی در فضای دیجیتال با بیش از یک اسم شناخته میشود.هنرمندی که یک «نام هنری» دارد، کسبوکاری که یک «اسم برند»...

چرا ناپدید شدن نالجپنل ناگهانی می شود 2025 ؟
ناپدید شدن ناگهانی نالجپنل؛ یک بحران واقعی در هویت دیجیتال ناپدید شدن نالجپنل | برای بسیاری از برندها، هنرمندان، شرکتها و حتی شخصیتهای عمومی، نالجپنل مثل یک «کارت ملی دیجیتال» است؛ سند رسمیای که گوگل به جهان نشان میدهد و...
اثر فعالیت ویدئویی بر نالجپنل | نقش YouTube و Shorts در تقویت Knowledge Graph 2025
چرا ویدئو به یکی از مهمترین سیگنالهای تقویت نالجپنل تبدیل شده است؟ اثر فعالیت ویدئویی بر نالجپنل | زمانی که گوگل شروع به ساختن «مدل معنایی جهان» کرد، هیچکس تصور نمیکرد که ویدئو به چنین ستون مهمی در تشخیص و...

