اعتبارسنجی نالج پنل چگونه است 2025 ؟
نقش “Verification Layer” در تأیید موجودیتها در گوگل
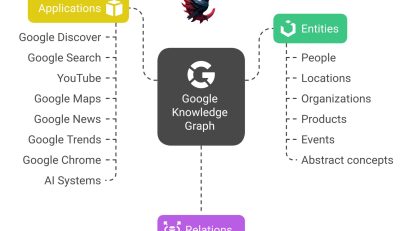
اعتبارسنجی نالج پنل | در جهان گستردهٔ گراف دانش گوگل، هیچ موجودیتی صرفاً با چند لینک یا چند بار سرچ شدن به نالجپنل نمیرسد. هر موجودیت قبل از اینکه وارد این ساختار پیچیده شود، باید از یک مسیر چندمرحلهای عبور کند که گوگل آن را «Verification Layers» یا لایههای اعتبارسنجی مینامد. این لایهها درواقع فیلترهایی هستند که هر برند، فرد یا سازمان باید از آنها عبور کند تا گوگل مطمئن شود با یک «هویت واقعی، دقیق و قابلاتکا» طرف است.
این همان نقطهای است که بسیاری از برندها، هنرمندان، متخصصان و حتی شرکتهای بزرگ از آن بیخبرند و تصور میکنند داشتن چند رپورتاژ یا چند پروفایل کافی است. اما در عمل، گوگل یک سیستم چندلایهای دارد که در آن هر مرحله سطح جدیدی از اطمینان را بررسی میکند. الگوریتم نه عجله دارد و نه تحت تأثیر تبلیغات یا حجم لینکها قرار میگیرد؛ بلکه دنبال یک چیز است: اعتماد قابل اثبات.
Verification Layer دقیقاً همان جایی است که تصمیم گرفته میشود یک شخص یا برند «موجودیت» محسوب میشود یا فقط یک «نام» باقی میماند.
بسیاری از موجودیتها به دلیل عبور نکردن از این لایهها، حتی با وجود ۲۰–۳۰ citation معتبر، هنوز نالجپنل نمیگیرند.
و در مقابل، برخی افراد با ساختار دادهٔ درست، حتی با ۵–۶ سیگنال وارد Knowledge Graph میشوند.
گوگل برای اینکه بتواند میلیاردها موجودیت را مدیریت کند، به یک سیستم لایهای نیاز داشت:
- لایهٔ اول: اعتبار پایهای (Basic Verification)
آیا این شخص یا برند واقعاً وجود دارد؟
آیا حداقل دو منبع مستقل او را تایید کردهاند؟ - لایهٔ دوم: تطابق هویتی (Identity Matching Layer)
آیا اطلاعات موجود در منابع مختلف با هم سازگار است؟
آیا نسخههای مختلف یک نام، یک فرد هستند؟ - لایهٔ سوم: اعتماد منبع (Source Trust Layer)
منابعی که درباره او حرف میزنند چه میزان معتبرند؟
آیا سازمانی هستند یا شخصی؟ - لایهٔ چهارم: ثبات اطلاعات (Consistency Layer)
آیا اطلاعات تغییرات زیادی داشته؟
آیا تناقض وجود دارد؟ - لایهٔ پنجم: زمینهٔ فعالیت (Profession / Context Layer)
این موجودیت در چه دستهای قرار دارد؟
سلامت؟ سرگرمی؟ تجارت؟ علمی؟
سطح حساسیت شغل چقدر است؟ - لایهٔ ششم: سیگنالهای رفتار کاربر (Behavior Signals)
آیا کاربران این موجودیت را جستجو میکنند؟
و آیا رفتار آنها با دادههای موجود همخوانی دارد؟
این لایهها پشتصحنهٔ فعال شدن هر نالجپنل هستند. اگر موجودیتی در یکی از این لایهها گیر کند، فرآیند فعالسازی متوقف میشود—حتی اگر Citationهای قدرتمند داشته باشد.
جالبتر اینکه گوگل این لایهها را به شکل کاملاً پویا به کار میگیرد. برای مثال ممکن است یک متخصص پزشکی با سه Citation معتبر، سریعتر از یک برند بزرگ با سی Citation وارد این ساختار شود، چون پزشک در لایهٔ حرفهای (Profession Layer) امتیاز بالاتری دارد. یا ممکن است یک هنرمند فقط به دلیل تناقض اطلاعاتی در لایهٔ Identity Matching، ماهها یا حتی سالها در انتظار نالجپنل باقی بماند.
درک نقش این لایهها دقیقاً همان جایی است که یک متخصص نالجپنل میتواند مسیر فعالسازی را چند برابر سریعتر کند. اگر کسی فقط به دنبال لینکسازی یا انتشار خبر باشد، معمولاً در لایهٔ سوم گیر میکند. اما اگر دادهها از ابتدا مطابق لایههای ۱ تا ۵ طراحی شوند، گوگل بدون مقاومت موجودیت را میپذیرد.
در این مقاله وارد عمق ماجرا میشویم: اینکه گوگل چطور این لایهها را اجرا میکند، چه موجودیتهایی سریعتر عبور میکنند، کجاها الگوریتم متوقف میشود، و چگونه یک برند میتواند این سیستم را بهنفع خودش طراحی کند.
📞 برای مشاورهٔ تخصصی ساخت نالجپنل و عبور از لایههای اعتبارسنجی گوگل: 09127079841
لایهٔ اول Verification در گوگل: آیا موجودیت واقعاً وجود دارد؟
در هر سیستم هوشمند، اولین سؤال همیشه ساده بهنظر میرسد: «این موجودیت واقعاً وجود دارد یا خیر؟»
اما برای گوگل، پاسخ دادن به همین سؤال ساده یکی از پیچیدهترین چالشهای دانشمحور است. جهان دیجیتال پر است از نامهای مشابه، صفحات جعلی، پروفایلهای ساختگی، کسبوکارهای یکشبه و موجودیتهایی که در یک پلتفرم وجود دارند ولی در پلتفرم دیگر هیچ اثری از آنها نیست. به همین دلیل، لایهٔ اول Verification در گوگل یکی از مهمترین مؤلفههای فعالسازی نالجپنل است—و اتفاقاً همان لایهای است که بیشترین شکستها در آن رخ میدهد.
گوگل قبل از اینکه حتی وارد بحث citation، محتوا، رسانه یا لینک شود، باید یک مسئله را حل کند:
آیا این موجودیت اصلاً واقعی است؟
و اگر واقعی است، آیا این اطلاعات مربوط به همان موجودیت است یا نه؟
در این لایه، گوگل به شکل وسواسگونهای به دنبال پاسخ این چهار سؤال میرود:
- آیا حداقل دو یا سه منبع مستقل این موجودیت را معرفی کردهاند؟
- آیا این منابع از یکدیگر کپی نشدهاند؟
- آیا اطلاعات اولیه (نام، حوزه، وابستگی) در این منابع سازگار است؟
- آیا هویت این موجودیت به راحتی با موجودیتهای دیگر اشتباه گرفته نمیشود؟
اینها ساده بهنظر میرسند، اما برای الگوریتم، تفاوت میان یک شخص واقعی و یک «نام تکراری» بسیار حیاتی است.
برای همین، لایهٔ اول بهنوعی دروازهٔ اصلی Knowledge Graph است.
چرا این لایه اینقدر سختگیرانه است؟
اعتبارسنجی نالج پنل | زیرا تمام لایههای بعدی—از تطابق هویتی گرفته تا اعتماد منبع و Citation Weight—بهطور کامل وابسته به این لایه هستند. اگر موجودیت اشتباه باشد، کل گراف اشتباه میشود. یک اشتباه کوچک در این لایه میتواند به نمایش اطلاعات غلط دربارهٔ یک پزشک، یک برند، یک سیاستمدار یا حتی یک سازمان منجر شود؛ چیزی که برای گوگل غیرقابلقبول است.
به همین دلیل، گوگل در لایهٔ اول دو اصل طلایی دارد:
اصل اول: حداقل دو منبع مستقل (Independent Existence Signals)
منابع باید از یکدیگر مستقل باشند—یعنی:
- یکی سایت رسمی
- یکی دایرکتوری
- یکی خبرگزاری
- یکی مقاله یا citation معتبر
اگر سه منبع وجود داشته باشد اما هر سه از یک وبسایت کپی شده باشند، اعتبار آنها صفر میشود.
برای همین است که رپورتاژهای «کپیشده» یا لینکهایی با الگوی یکسان، در این لایه تقریباً بیاثر هستند.
اصل دوم: تطابق اطلاعات پایه (Primary Data Consistency)
گوگل در این لایه به دنبال دادههای پایه میگردد:
- نام دقیق
- عنوان شغلی
- کشور/شهر
- وبسایت رسمی
- وابستگی سازمانی
اگر حتی یکی از اینها در منابع مختلف متفاوت باشد، لایهٔ اول رد میشود و گوگل موجودیت را «uncertain» علامت میزند.
بهطور مثال:
- در یک سایت «دکتر»، در سایت دیگر «کارشناس»، در سایت سوم «مشاور»
- یا یک برند در یک جا سال تأسیس ۲۰۱۸ دارد، جای دیگر ۲۰۲۱
- یا نام فرد در یک جا «Ali Reza» و در جای دیگر «Alireza» نوشته شده است
در چنین مواردی، حتی وجود دهها لینک هم باعث فعالسازی نمیشود.
چرا پزشکان در این لایه سریع عبور میکنند؟
دلیلش ساده است:
وجود در پایگاههای رسمی و سازمانی.
پزشکان تقریباً همیشه پروفایلهای زیر را دارند:
- بیمارستان
- کلینیک
- نظام پزشکی
- دانشگاه
- انجمن تخصصی
اینها منابع مستقل، سازمانی و بسیار معتبر هستند.
بنابراین گوگل در همان دقیقهٔ اول، موجودیت را واقعی فرض میکند.
در مقابل، یک هنرمند یا یک برند تازهکار ممکن است فقط:
- یک سایت شخصی
- یک پیج اینستاگرام
- یک مصاحبه
- یک رپورتاژ
داشته باشد.
اینها برای گوگل کافی نیست.
نتیجه؟
پزشکان لایهٔ اول را تقریباً «خودکار» عبور میکنند، اما سایر مشاغل در این مرحله گیر میکنند.
برندها و افراد چگونه میتوانند از این لایه عبور کنند؟
اینجاست که استراتژی واقعی شروع میشود.
برای عبور از این لایه، باید:
- حداقل سه منبع مستقل و غیروابسته ایجاد شود.
- سایت رسمی
- رسانه معتبر
- دایرکتوری رسمی
- صفحهٔ ثبتشده در دیتابیس قابل کراول
- اطلاعات پایه کاملاً هماهنگ باشد.
یکسان بودن:- نام
- عنوان شغلی
- سال فعالیت
- بیوگرافی کوتاه
- لینک اصلی
- تناقضها حذف شود.
کوچکترین تفاوتی مثل تغییر سال تولد یا تغییر عنوان، کافی است تا گوگل این لایه را رد کند. - citation سازمانی ساخته شود، نه شخصی.
مثلاً:- Crunchbase
- Latium
- GoodFirms
- دانشگاه
- کتابخانه ملی
- خبرگزاری واقعی
بدون اینها، موجودیت هرگز وارد لایهٔ دوم نمیشود.
Identity Matching Layer: گوگل چطور تشخیص میدهد همهٔ دادهها متعلق به یک موجودیت واحد هستند؟
بعد از اینکه موجودیت از لایهٔ اول Verification عبور کرد، گوگل هنوز نمیتواند آن را وارد Knowledge Graph کند.
چون یک مسئلهٔ بسیار بزرگ باقی میماند:
آیا دادههایی که دربارهٔ این موجودیت منتشر شده، همه متعلق به یک فرد است؟ یا بخشی از آن مربوط به افراد همنام یا برندهای مشابه است؟
این دقیقاً همان جایی است که لایهٔ دوم وارد میشود:
Identity Matching Layer.
در این لایه، گوگل به دنبال پاسخ دادن به یک سؤال بسیار سخت است:
«آیا این دادهها واقعاً به یک Entity واحد تعلق دارد؟»
این لایه حیاتیترین لایهٔ نالجپنل است، چون حتی یک اشتباه کوچک میتواند باعث ایجاد «Entity Mixing» شود—یعنی گوگل اطلاعات دو فرد متفاوت را با هم قاطی کند. چنین خطایی برای موتور جستجو خطرناک است، بهخصوص در حوزههایی مثل پزشکان یا افراد عمومی. بنابراین، گوگل در این مرحله بسیار سختگیرانه رفتار میکند.
گوگل در Identity Matching چه چیزهایی را بررسی میکند؟
۱) یکنواختی نام (Name Consistency)
کوچکترین تفاوت در نام باعث میشود گوگل دادهها را به موجودیت جداگانه نسبت دهد.
مثلاً:
- علی رضا / علیرضا
- Mohammad Reza / Mohammadreza
- Dr. Sara Khalili / Sara Khalili
از نگاه انسان تفاوت کوچک است؛ اما از نگاه الگوریتم، تعیینکننده.
برای همین است که برندها باید در تمام citationها از یک استاندارد نام واحد استفاده کنند.
۲) یکنواختی عنوان شغلی (Professional Identity)
این دقیقاً همانجایی است که بیشترین اشتباهها رخ میدهد.
اگر شخصی در یک سایت «کارآفرین» معرفی شده، در سایت دیگر «استراتژیست دیجیتال»، و در سایت سوم «موزیسین»، الگوریتم به شدت سردرگم میشود.
برای پزشکان مشکلی نیست؛
در همهجا «متخصص قلب» = «متخصص قلب».
اما برای مشاغل دیگر، تنوع عنوان باعث شک گوگل میشود.
۳) اطلاعات مکانی (Location Identity)
گوگل برای تشخیص موجودیت واحد از سه نوع دادهٔ مکانی استفاده میکند:
- شهر فعلی
- کشور
- محل فعالیت سازمانی
اگر در یک سایت نوشته شده «تهران»، در دیگری «استانبول»، در سومی «امارات»، الگوریتم به این نتیجه میرسد:
«اینها احتمالاً سه فرد متفاوت هستند.»
حتی اگر واقعیت اینطور نباشد.
۴) یکنواختی لینکها و حضور پلتفرمی (Platform Identity)
گوگل بررسی میکند:
- آیا همهٔ پروفایلها به یک سایت رسمی لینک میشوند؟
- آیا شبکههای اجتماعی معتبر یکسان هستند؟
- آیا بیوگرافیها یکدیگر را تأیید میکنند؟
اگر فردی سه اینستاگرام دارد، دو سایت دارد، یا چند پروفایل مشابه دارد، الگوریتم هویت او را «Unstable Identity» تشخیص میدهد.
این همان دلیل اصلی بود که بسیاری از هنرمندان و اینفلوئنسرها با وجود شهرت بالا، سالها نالجپنل نگرفتند.
چرا پزشکان باز هم سریعتر عبور میکنند؟
پزشکان در این لایه تقریباً همیشه برندهاند، چون:
- یک نام رسمی دارند
- یک تخصص ثابت دارند
- یک محل فعالیت ثابت دارند
- یک سازمان رسمی آنها را معرفی میکند
- تناقض در دادههای آنها تقریباً صفر است
وقتی یک پزشک در سه سایت معتبر معرفی میشود، همه چیز کاملاً یکی است:
- یک نام
- یک تخصص
- یک آدرس
- یک شماره مجوز
در نتیجه گوگل میگوید:
«این چند منبع، ۱۰۰٪ یک فرد را توصیف میکنند.»
اما برای یک برند یا آدم مشهور، دادهها هرگز اینقدر ساده نیست.
بزرگترین دلیل شکست برندها در این لایه: تناقض اطلاعاتی
برندها معمولاً این اشتباهات مرگبار را دارند:
- تاریخ تأسیس متفاوت
- عددهای متفاوت کارمندان
- حوزه فعالیت متغیر
- بیوگرافیهای مختلف
- لینکهای شکسته
- چند سایت مختلف
- رپورتاژهای متنکپیشده
- شباهت اسمی با برندهای دیگر
این تناقضها باعث میشود گوگل فکر کند:
«من هنوز مطمئن نیستم این دادهها متعلق به یک موجودیت واحد هستند؛ پس نمیتوانم نالجپنل فعال کنم.»
درواقع ۶۰٪ موجودیتها همینجا گیر میکنند.
چطور باید این مشکل را برای برندها حل کرد؟
برای عبور از لایهٔ Identity Matching، باید:
- یک نسخهٔ طلایی هویت بسازیم (GOLDEN ENTITY FILE)
شامل:- نام دقیق
- عنوان دقیق
- تاریخ دقیق
- حوزهٔ فعالیت دقیق
- نسخه رسمی بیوگرافی
- تمام citationهای جدید باید از این نسخه تبعیت کنند.
- تمام تناقضها حذف شود.
- سایت رسمی بهعنوان منبع مرکزی معرفی شود.
- پروفایلهای شبکههای اجتماعی یکپارچه گردد.
- هیچ اطلاعات متناقضی باقی نماند—even کوچکترینش.
این دقیقاً همان کاری است که در پروژههای نالجپنل حرفهای باید انجام شود:
رویکردی مهندسیشده، نه رپورتاژمحور.
اهمیت این لایه برای نتیجه نهایی
تا زمانی که هویت یک موجودیت برای گوگل ثابت نشده باشد،
هیچ مقدار از:
- لینکسازی
- رپورتاژ
- citation
- محتوا
- رفتار کاربر
نمیتواند نالجپنل را فعال کند.
Identity Matching هستهٔ اصلی گراف دانش است—و دلیل اصلی تفاوت میان «یک نام» و «یک موجودیت».
Source Trust Layer: گوگل چطور اعتبار هر منبع را اندازهگیری میکند؟
وقتی موجودیت از مرحلهٔ تطابق هویتی عبور کرد، نوبت به یکی از مهمترین لایههای سیستم Verification میرسد:
Source Trust Layer
یا همان «لایهٔ سنجش اعتماد منابع».
در این مرحله، دیگر صرف وجود citation مهم نیست؛
مهم این است که چه کسی دربارهٔ موجودیت حرف میزند.
چرا که برای گوگل، هر سایتی ارزش یکسان ندارد.
یک پروفایل در سایت بیمارستان میتواند اندازهٔ ۲۰ رپورتاژ ارزش داشته باشد، درحالیکه یک وبسایت بلاگر ممکن است حتی صفر امتیاز داشته باشد—even اگر مقالهٔ خیلی خوبی دربارهٔ فرد نوشته باشد.
در این لایه، گوگل نه تنها کیفیت منبع را تحلیل میکند، بلکه نگاه میکند «این منبع چه جایگاهی در گراف دانش دارد».
یعنی ارزشسنجی منابع دیگر را هم در نظر میگیرد تا برای هر citation وزن دقیق تعریف کند.
گوگل اعتبار منابع را چگونه ارزیابی میکند؟
در این لایه، الگوریتم به سه جنبهٔ کلیدی نگاه میکند:
۱) ماهیت منبع (Nature of the Source)
منابع اینترنتی به چهار دسته تقسیم میشوند:
الف) منابع سازمانی (Institutional Sources)
مثل:
- دانشگاهها
- بیمارستانها
- اتاق بازرگانی
- سازمانهای دولتی
- دیتابیسهای تخصصی
- بنیادها و انجمنهای رسمی
اینها بالاترین وزن ممکن را دارند و بیشترین تأثیر را بر نالجپنل میگذارند.
ب) منابع خبری معتبر (Top-Tier News)
فقط رسانههایی که اعتبار جهانی یا داخلی بالا دارند:
- BBC
- Forbes
- Reuters
- Associated Press
- ایرنا
- ایسنا
- همشهری
- دنیای اقتصاد
و…
اینها در سطح دوم قرار میگیرند.
ج) منابع میانی (Mid-Tier Media + Blogs)
مثل:
- سایتهای محتوایی
- وبلاگهای معتبر
- رسانههای تخصصی
- نشریات آنلاین
اینها اثرگذارند، اما وزن آنها محدود است.
د) منابع شخصی (Low-Tier / Self-Published)
مثل:
- وبسایت شخصی
- شبکههای اجتماعی
- رپورتاژهای تبلیغاتی
- پیجهای خبری کوچک
اینها کمترین وزن را دارند و معمولاً در لایههای اولیه تأثیر چندانی ندارند.
۲) اعتبار نویسنده و دامنه (Source Authority & Domain History)
گوگل رفتار سایت را در طول زمان بررسی میکند:
- آیا سالهاست فعال است؟
- آیا اطلاعاتش دقیق بوده؟
- آیا کاربران به آن اعتماد کردهاند؟
- آیا سابقهٔ اشتباه یا انتشار اخبار جعلی دارد؟
- آیا در گراف دانش بهعنوان منبع معتبر قبلاً ثبت شده؟
این همان جایی است که سایتهای سازمانی همیشه پیروز هستند.
در مقابل، سایتهایی مثل رپورتاژهای تکراری، وبلاگهای ضعیف، سایتهای تازه تأسیس یا دامنههای اجارهای تقریباً هیچ امتیازی ایجاد نمیکنند—even اگر محتوا خوب باشد.
۳) تطابق محتوا با سایر منابع (Cross-Source Confirmation)
یک منبع زمانی ارزشمند است که اطلاعاتش توسط یک منبع دیگر «تأیید» شود.
گوگل بررسی میکند:
- آیا اطلاعات این سایت با منابع دیگر یکسان است؟
- آیا تفاوت فاحشی در سال تولد، عنوان شغلی، یا حوزه فعالیت وجود ندارد؟
- آیا دادهٔ ارائهشده قابل اعتماد و منطقی است؟
اگر یک سایت اطلاعات متفاوتی ارائه دهد—even اگر خیلی معتبر باشد—وزن آن کاهش مییابد، چون الگوریتم شروع به شککردن میکند.
چرا پزشکان در Source Trust Layer تقریباً همیشه بالاترین امتیاز را میگیرند؟
چون پزشکان سه نوع citation دارند که هر سه جزو بالاترین سطح اعتماد هستند:
- سایت بیمارستان یا کلینیک → منبع سازمانی
- نظام پزشکی یا انجمن تخصصی → منبع هویتی معتبر
- مقالات علمی یا دانشگاهی → منبع high-trust
ترکیب این سه باعث میشود:
- وزن citation پزشکان ۲ تا ۴ برابر سایر مشاغل باشد
- الگوریتم عملاً بدون نیاز به چند منبع دیگر، موجودیت را تأیید کند
- مسیر فعالسازی نالجپنل بسیار کوتاه شود
برای همین است که پزشکان با ۳ citation وارد Knowledge Graph میشوند، اما برندها با ۱۵ citation هنوز معلق هستند.
چرا برندها و افراد دیگر در این لایه گیر میکنند؟
به چهار دلیل:
۱. منابع سازمانی ندارند
اگر یک برند فقط:
- رپورتاژ
- وبلاگ
- و صفحهٔ اینستاگرام
داشته باشد، عملاً در این لایه صفر امتیاز میگیرد.
۲. منابعشان self-published است
سایت خود فرد → کموزن
پستهای شبکههای اجتماعی → تقریباً بیتأثیر
رپورتاژهای کپیشده → بیارزش
۳. منابع معتبر دربارهشان صحبت نکردهاند
هیچ سایت بزرگ یا سازمانی آنها را تأیید نکرده.
۴. تناقض اطلاعات در منابع مختلف
حتی کوچکترین تناقض باعث سقوط امتیاز اعتماد میشود.
چطور میتوان این لایه را برای یک برند تقویت کرد؟
این مرحله نیاز به «طراحی مهندسیشده» دارد، نه جمع کردن لینک بیهدف.
برای عبور از این لایه باید:
- Citation سازمانی ساخته شود
مثل:
- Crunchbase
- Google Books
- Apple Podcasts
- دانشگاه
- ثبت شرکت
- LexisNexis
- Bloomberg (برای برندهای بزرگ)
- رسانه معتبر واقعی وارد کار شود
حداقل یک منبع خبری High-Tier. - Consistency کامل میان دادهها
هیچ تناقضی در سال تأسیس، حوزه فعالیت، نام یا ساختار بیو وجود نداشته باشد. - استفاده از لینکهای authoritative در سایت رسمی
تا گوگل سایت مرکزی را با منابع دیگر match کند.
نتیجهٔ اصلی
Source Trust Layer همان لایهای است که پزشکان را ۳ برابر سریعتر از دیگران به نالجپنل میرساند.
چون منابع آنها سازمانی، معتبر و هماهنگ است.
برندها هم اگر این لایه را درست بسازند، سرعت فعالسازیشان چند برابر میشود—even اگر شغلشان حساسیت پزشکی نداشته باشد.
Consistency Layer: چرا یک تناقض کوچک میتواند کل فعالسازی نالجپنل را متوقف کند؟
وقتی موجودیت از لایههای «وجود واقعی»، «تطابق هویتی» و «اعتبار منابع» عبور کرد، یک چالش دیگر باقی میماند—چالشی که معمولاً سختتر از همه است:
آیا تمام دادههای موجود در اینترنت دربارهٔ این موجودیت با یکدیگر هماهنگ هستند؟
این همان «Consistency Layer» است.
در این لایه، گوگل از خود یک سؤال مهم میپرسد:
«آیا تصویر کلیای که از این موجودیت دارم، بدون تناقض است؟
اگر این دادهها را وارد گراف کنم، آیا بعدها مجبور میشوم اصلاح کنم؟»
اگر پاسخش حتی کمی مشکوک باشد، فعالسازی نالجپنل فوراً متوقف میشود.
بدون هشدار.
بدون اعلام.
بدون ارور.
برای همین است که بسیاری از برندها، هنرمندان یا متخصصان—even با Citationهای قوی—باز هم نالجپنل نمیگیرند.
مشکل در ۹۰٪ موارد همین لایه است: عدم هماهنگی اطلاعات.
چرا گوگل اینقدر روی Consistency حساس است؟
چون گراف دانش یک سیستم «کُند، دقیق و پایدار» است.
وقتی یک داده وارد گراف شود، به هزاران ویژگی و زیرموجودیت وصل میشود.
اصلاح آن بسیار سخت است، و اشتباه میتواند روی میلیونها کاربر اثر بگذارد.
برای همین گوگل ترجیح میدهد:
- هیچ نالجپنلی نمایش ندهد
تا اینکه - یک نالجپنل اشتباه نمایش دهد
این اصل برای گوگل از هرچیزی مهمتر است.
بالاخره چه چیزهایی باعث تناقض میشوند؟
۱) تفاوت در نام یا فرمت نام
مثلاً:
- “Dr. Sara M. Khalili”
- “Sara Khalili”
- “Dr Sara Khalili”
یا
“AliReza” vs “Alireza”
این تفاوتها کوچک هستند، اما برای الگوریتمِ matching داده مثل کابوسند.
۲) اختلاف در عنوان شغلی یا حوزه فعالیت
مثلاً:
- “Digital Marketer”
- “Entrepreneur”
- “Content Creator”
- “Musician”
برای گوگل مشخص نیست:
این اطلاعات مربوط به یک نفر است یا افراد مختلف؟
هر تغییری در عنوان شغلی اگر بدون ساختار انجام شود، Consistency را از بین میبرد.
۳) سال تأسیس متفاوت در منابع مختلف
برندها معمولاً این اشتباه را میکنند:
- سایت رسمی نوشته ۲۰۱۹
- مصاحبه نوشته ۲۰۱۸
- رپورتاژ نوشته ۲۰۲۱
چنین تناقضی باعث میشود گوگل بگوید:
«تا زمانی که نفهمم کدام درست است، موجودیت را فعال نمیکنم.»
۴) تفاوت در تعداد کارمندان یا مقیاس کسبوکار
مثلاً:
- “10+ employees”
- “30 employees”
- “Freelance team”
اختلاف در اعداد باعث بیاعتمادی الگوریتم میشود.
۵) لینکهای شکسته یا منابع قدیمی
وقتی چند citation به آدرسهای 404 یا صفحات حذفشده اشاره کنند، گوگل تصور میکند داده پایدار نیست.
۶) تغییرات شدید در یک بازهٔ زمانی کوتاه
یکی از رفتارهای مشکوک برای گوگل این است:
- تغییر ناگهانی بیو
- تغییر ناگهانی عنوان شغلی
- تغییر ناگهانی محل فعالیت
- تغییر صفحهٔ رسمی برند
این تغییرات شبیه «Manipulation» دیده میشوند و از نظر الگوریتم خطرناکاند.
چرا پزشکان باز هم برندهاند؟
تمام چیزهایی که باعث تناقض میشوند، در حوزهٔ پزشکی تقریباً وجود ندارند:
- نام ثابت
- تخصص ثابت
- مکان ثابت
- سایت بیمارستان با دادهٔ پایدار
- شمارهٔ مجوز ثابت
- citation سازمانی یکپارچه
به همین دلیل پزشکان بهطور طبیعی Consistency کامل دارند—even اگر خودشان هم ندانند.
در مقابل، مشاغل دیگر بهطور طبیعی پراکندگی اطلاعات دارند.
بزرگترین اشتباه برندها در این لایه: تولید پرتعداد دادهٔ ناسازگار
برندها و افراد معمولاً فکر میکنند:
«هرچه بیشتر محتوا تولید کنم، گوگل سریعتر ایمان میآورد.»
اما واقعیت این است:
هرچه بیشتر محتوا تولید کنی، احتمال تناقض بیشتر میشود.
هرچه تناقض بیشتر شود، احتمال فعالسازی کمتر میشود.
Consistency یعنی «کم اما دقیق».
پزشکان دقیقاً همین کار را میکنند.
چگونه یک برند میتواند Consistency Layer را پاس کند؟
۱) ساخت یک فایل هویت واحد (Golden Entity File)
یک سند مرکزی شامل:
- نام رسمی
- عنوان ثابت
- تاریخ تأسیس
- بیو ثابت
- لینک رسمی
- محل فعالیت
- لوگو
این فایل باید «قانون مادر» باشد.
۲) هماهنگسازی تمام citationها با این نسخهٔ مادر
هر صفحهٔ پروفایل، هر خبر، هر بیو، هر رپورتاژ و هر لینک باید از این نسخه تبعیت کند.
۳) حذف تمام تناقضات قبلی
دیتاهای قدیمی، پروفایلهای اضافی، بیوهای متفاوت—همه باید حذف یا اصلاح شوند.
۴) تغییرات تدریجی، نه ناگهانی
گوگل از تغییرات ناگهانی بیزار است.
اصلاحات باید آرام و مرحلهبهمرحله انجام شوند.
۵) لینک مرکزی ثابت و قابل اعتماد
تمام citationها باید به یک سایت رسمی واحد اشاره کنند.
نتیجهٔ این لایه
Consistency Layer جایی است که:
- پزشکان موفق میشوند
- برندها گیر میکنند
و دلیلش این است:
پزشکان دادهٔ پایدار و استاندارد دارند.
برندها دادهٔ زیاد اما ناپایدار دارند.
پاسکردن این لایه یعنی گوگل آمادهٔ ورود موجودیت به لایههای نهایی Verification است.
Behavior & Engagement Verification Layer
تا این لحظه تمام لایههای قبلی—از وجود واقعی تا تطابق هویتی، Consistency، Citationها و E-E-A-T—چیزی شبیه «مدارک اولیه» هستند.
اما گوگل یک نگاه دیگر هم دارد:
آیا مردم به این موجودیت توجه میکنند؟
اگر بله، نالجپنل فعال میشود.
اگر نه، تمام آن مدارک قبلی ممکن است بیاثر شوند.
به همین دلیل به این مرحله میگوییم:
لایهٔ تأیید نهایی توسط کاربر (User-Driven Verification).
چرا گوگل رفتار کاربران را معیار نهایی میگذارد؟
چون بهترین سیگنال این است:
اگر یک موجودیت واقعاً مهم باشد، مردم به آن واکنش نشان میدهند.
- سرچ میکنند
- کلیک میکنند
- تعامل میکنند
- بازدید تکراری دارند
- دربارهاش محتوا تولید میکنند
گوگل از این رفتارها میفهمد:
«این موجودیت زندهست، نه یک پروفایل ساختگی.»
برندهای بیتعامل—even با بهترین citation—از این مرحله رد نمیشوند.
مهمترین رفتارهایی که گوگل اندازه میگیرد
۱) جستجوی نام برند یا فرد (Brand Query Demand)
قویترین سیگنال موجود.
اگر کسی در گوگل سرچ نشود،
گوگل هم به او نالجپنل نمیدهد.
فرق قضیه:
- Dr. X → جستجوهای ماهانه بالا
- یک برند ناشناخته → صفر یا بسیار کم
گوگل این را «دلیل کافی برای ثبت موجودیت» میداند.
۲) نرخ کلیک (CTR) روی نتیجه رسمی
وقتی کاربران روی لینکهای زیر زیاد کلیک کنند:
- سایت رسمی
- ویکی
- News Article
- Profile Databases
گوگل میفهمد:
«این موجودیت برای این کاربر مهم است.»
مثلاً اگر کسی نام شما را سرچ کند و روی سایت رسمیتان کلیک کند،
این برای گوگل یک چراغ سبز است.
۳) رفتار جستجوی تکراری (Repeated Queries)
اگر یک موجودیت «بارها» سرچ شود،
نه فقط یکبار، آنوقت گوگل تشخیص میدهد:
این موجودیت پایدار و پیوسته مورد توجه مردم است.
پزشکان، هنرمندان، سیاستمداران—به همین دلیل سریع فعال میشوند.
۴) جستجوی مرتبط (Entity Related Queries)
مثلاً:
- «Dr. X Clinic»
- «Dr. X appointment»
- «Dr. X reviews»
یا برای برندها:
- «Boofee Coffee Review»
- «C-Persian services»
- «Safaee musician age»
اینها سیگنال میدهد:
کاربران دربارهٔ ابعاد مختلف موجودیت کنجکاوند.
۵) رفتار در مرورگر (Chrome Behavior Signals)
ممکن است عجیب بهنظر برسد،
اما گوگل از طریق Chrome هم رفتار کاربران را میسنجد:
- آیا کاربران با سرچ نام شما وارد سایت میشوند؟
- آیا مدت طولانی در سایت میمانند؟
- آیا دوباره برمیگردند؟
همهٔ اینها «سیگنال تأیید» حساب میشود.
۶) رفتار کاربران در یوتیوب و جیمیل
برای هنرمندان خیلی مهم است:
- سرچ نام در یوتیوب
- تماشای ویدیوهای مرتبط
- ذخیرهسازی یا subscribe
اینها بهطور مستقیم روی Knowledge Graph تأثیر دارد.
چرا پزشکان دوباره پیروز ماجرا میشوند؟
چون رفتار کاربران در حوزه پزشکان همیشه واقعی و مداوم است:
- سرچ نام پزشک
- آدرس مطب
- نظرات بیماران
- سوال درباره تخصص
- نوبتگیری
- مقایسه با پزشکان دیگر
این حجم از engagement باعث میشود:
گوگل حتی زودتر از خود پزشک، برایش موجودیت فعال کند.
چرا برندها در این لایه گیر میکنند؟
سه دلیل اصلی:
۱) جستجو ندارند
برند تازهتأسیس یعنی:
- ۰ سرچ
- ۰ ارتباط زنجیرهای
- ۰ کاربر واقعی
گوگل هم میگوید:
«فعلاً پرچم سفید.»
۲) رفتار ساختگی تشخیص داده میشود
افزایش جستجوی مصنوعی یا click-farm فوری شناسایی میشود.
گوگل هزار شاخص دارد:
- ناهمگونی IP
- سرعت رشد غیرعادی
- الگوهای تکراری
- نبود رفتارهای طبیعی جانبی
حتی اگر ۳۰ روز سیستم را فریب دهید،
در نهایت نالجپنلتان را حذف میکند.
۳) Engagement واقعی در سایت وجود ندارد
کاربران وارد سایت نمیشوند.
یا وارد میشوند اما سریع خارج میشوند.
این یعنی:
برند هنوز «وجود دیجیتال واقعی» ندارد.
پس چطور یک برند میتواند این لایه را بگذراند؟
۱) ایجاد Demand واقعی
واسه برند باید دلیل ساخته شود که مردم نامش را سرچ کنند:
- تبلیغ درست
- کمپین هدفمند
- خبر معتبر
- حضور رسانهای
نه سرچهای مصنوعی.
۲) بهینهسازی صفحه رسمی
چیزی که کاربران ببینند و بگویند:
«ارزشش را دارد برگردم.»
۳) ساخت محتوا در حوزههای مرتبط
نه هر محتوا—
محتوایی که پرسونای واقعی مخاطب برایش ارزش قائل باشد.
۴) اتصال شبکههای اجتماعی به سایت رسمی
این برای ایجاد رفتار «جستجوی زنجیرهای» حیاتی است.
۵) افزایش تعامل ارگانیک
ریزش، رشد، تعامل، اشتراک—
همه باید طبیعی باشد.

زهرا عبدلی، نویسندهی محتوای فارسی در تیم سیپرشین است؛ فردی که با دقت و مسئولیت، نقش مؤثری در تولید محتوای هدفمند و معتبر برای برند ایفا میکند. او بخشی از مسیر رشد و کیفیت ماست.
مقالات مرتبط

عدم فعالسازی نالج پنل 202
چرا بعضی برندها هرگز نالجپنل نمیگیرند؟ عدم فعالسازی نالج پنل | اگرچه بسیاری از برندها تصور میکنند با داشتن یک سایت خوب، چند صفحه در شبکههای اجتماعی و حتی چند مقاله خبری، باید نالجپنلشان در گوگل فعال شود، اما واقعیت...